Of course! Using XGBoost on Linux with Python is a very common and powerful combination for machine learning, especially for tabular data. This guide will walk you through the entire process, from installation to training a model and making predictions.

Here's a structured breakdown:
- Prerequisites: What you need before you start.
- Installation: How to install XGBoost and its dependencies on Linux.
- A Simple Python Example: A complete, runnable script to train and predict.
- Key XGBoost Parameters: An explanation of the most important parameters to tune.
- Saving and Loading Models: How to persist your trained models.
- Advanced Topics: GPU acceleration, cross-validation, and feature importance.
- Troubleshooting: Common issues and their solutions.
Prerequisites
- A Linux Distribution: This guide applies to Ubuntu, Debian, CentOS, Fedora, etc.
- Python 3: XGBoost requires Python 3.6 or newer. You can check your version with:
python3 --version
- pip: Python's package installer. It usually comes with Python.
pip3 --version
- A C++ Compiler: XGBoost has C++ components that need to be compiled. This is usually handled automatically by
pip, but having a compiler installed can prevent errors.- On Debian/Ubuntu:
sudo apt-get update && sudo apt-get install build-essential - On CentOS/RHEL/Fedora:
sudo yum groupinstall "Development Tools"
- On Debian/Ubuntu:
Installation
The recommended way to install XGBoost is using pip. We'll also install scikit-learn and pandas, as they are essential for data handling and evaluation.
Step 1: Create a Virtual Environment (Highly Recommended)
This isolates your project's dependencies from your system's Python.
# Create a virtual environment named 'xgboost_env' python3 -m venv xgboost_env # Activate it source xgboost_env/bin/activate # Your terminal prompt should now change to show the active environment # (xgboost_env) $
Step 2: Install XGBoost and Dependencies
Now, inside your activated virtual environment, install the packages.

# Install XGBoost, scikit-learn, and pandas pip install xgboost scikit-learn pandas numpy
Note on GPU Support: If you want to use your NVIDIA GPU for training (which is significantly faster), you need to install a special version. First, make sure you have the NVIDIA CUDA Toolkit installed.
# Install the GPU-enabled version of XGBoost pip install xgboost[GPU]
A Simple Python Example (Classification)
Let's train a model to classify the famous Iris dataset. Create a file named train_iris.py and paste the following code into it.
# train_iris.py
import xgboost as xgb
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 1. Load the dataset
iris = load_iris()
X = iris.data
y = iris.target
# 2. Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 3. Initialize and train the XGBoost model
# 'objective': 'multi:softmax' for multi-class classification
# 'num_class': the number of classes in the dataset (3 for Iris)
# 'use_label_encoder': False is recommended to avoid a future warning
# 'eval_metric': 'mlogloss' is a common metric for multi-class classification
model = xgb.XGBClassifier(
objective='multi:softmax',
num_class=3,
use_label_encoder=False,
eval_metric='mlogloss',
n_estimators=100, # Number of boosting rounds (trees)
learning_rate=0.1,
random_state=42
)
print("Training the model...")
model.fit(X_train, y_train)
print("Training complete.")
# 4. Make predictions on the test set
y_pred = model.predict(X_test)
# 5. Evaluate the model's accuracy
accuracy = accuracy_score(y_test, y_pred)
print(f"Model Accuracy: {accuracy * 100:.2f}%")
# 6. (Optional) Show feature importance
print("\nFeature Importance:")
for i, importance in enumerate(model.feature_importances_):
print(f"Feature {i+1} ({iris.feature_names[i]}): {importance:.4f}")
How to Run the Script
Open your terminal, make sure your virtual environment is active, and run:
python3 train_iris.py
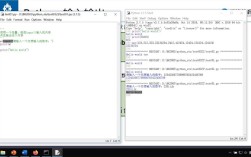
Expected Output:

Training the model...
Training complete.
Model Accuracy: 100.00%
Feature Importance:
Feature 1 (sepal length (cm)): 0.0183
Feature 2 (sepal width (cm)): 0.0229
Feature 3 (petal length (cm)): 0.7498
Feature 4 (petal width (cm)): 0.2090Key XGBoost Parameters
Understanding these parameters is crucial for getting good results.
| Parameter | Description | Common Values |
|---|---|---|
objective |
Defines the learning task. | 'reg:squarederror' (Regression), 'binary:logistic' (Binary Classification), 'multi:softmax' (Multi-class Classification) |
n_estimators |
The number of boosting rounds (i.e., the number of trees to build). | 100, 200, 500, 1000 (Higher is often better, but can lead to overfitting). |
learning_rate (or eta) |
Step size shrinkage used in update to prevent overfitting. | 01, 1, 2, 3. A lower value requires more trees (n_estimators). |
max_depth |
The maximum depth of a tree. Controls model complexity. | 3, 6, 10. Deeper trees can model more complex relationships but risk overfitting. |
subsample |
The fraction of samples to be used for fitting the individual base learners. | 8, 9, 0. Less than 1.0 introduces randomness and helps prevent overfitting. |
colsample_bytree |
The fraction of features to be used for fitting the individual base learners. | 8, 9, 0. Similar to subsample but for features. |
gamma (or min_split_loss) |
Minimum loss reduction required to make a further partition on a leaf node of the tree. | 0, 1, 2, 0. Higher values make the algorithm more conservative. |
reg_alpha (L1 regularization) |
L1 regularization term on weights. | 0, 01, 1, 0. Encourages sparsity (many weights become zero). |
reg_lambda (L2 regularization) |
L2 regularization term on weights. | 0, 1, 0, 0. Encourages small weights. |
Saving and Loading Models
It's inefficient to retrain a model every time you need to use it. XGBoost makes it easy to save and load models.
Saving a Model
You can save a model to a file in various formats.
# After training the model as shown in the example above
model.save_model('xgboost_iris_model.json') # Recommended JSON format
# Or use binary format
# model.save_model('xgboost_iris_model.bin')
Loading a Model
You can load the saved model and use it directly for predictions.
# Create a new model object
loaded_model = xgb.XGBClassifier()
# Load the model from the file
loaded_model.load_model('xgboost_iris_model.json')
# Now you can use it for predictions
# For example, predict the class for a single new sample
new_sample = [[5.1, 3.5, 1.4, 0.2]] # A known Iris setosa sample
prediction = loaded_model.predict(new_sample)
print(f"Prediction for new sample: {prediction[0]}") # Output: 0
print(f"Predicted class name: {iris.target_names[prediction[0]]}") # Output: setosa
Advanced Topics
GPU Acceleration
If you installed the xgboost[GPU] version and have CUDA installed, enabling GPU usage is often as simple as adding a parameter to your model.
# For XGBClassifier model = x