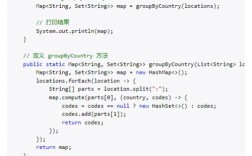
Of course! "ArcGIS Python style" isn't about a single, rigid set of rules, but rather a collection of best practices and conventions for writing clean, efficient, and maintainable Python code specifically for use with ArcGIS.

Here’s a comprehensive guide covering the key aspects of ArcGIS Python style, broken down into logical sections.
The Golden Rule: Readability is Paramount
The primary goal of any style guide is to make code easy for humans to read and understand. This is especially true in GIS, where projects can be complex, long-lived, and involve collaboration. A consistent style helps you and your colleagues quickly grasp what a script does, how it works, and how to modify it.
Naming Conventions (How to Name Things)
Consistent naming reduces confusion and makes your code self-documenting.
Variables and Functions (camelCase or snake_case)
Use snake_case for variables and functions. This is the most common and readable convention in Python.
-
Good:
input_feature_class = r"C:\Data\Parcels.shp" output_feature_class = r"C:\Data\Parcels_Projected.shp" def calculate_area(fc_path): # ... function logic pass -
Avoid (PascalCase):
InputFeatureClass = r"C:\Data\Parcels.shp" # PascalCase is for classes
Classes (PascalCase)
Use PascalCase (also known as CamelCase) for class names. This is a standard Python convention.
-
Good:
 (图片来源网络,侵删)
(图片来源网络,侵删)class ParcelAnalyzer: def __init__(self, feature_class): self.fc = feature_class def calculate_areas(self): # ... method logic pass
Constants (UPPER_SNAKE_CASE)
Use UPPER_SNAKE_CASE for constants—values that should never change.
- Good:
BUFFER_DISTANCE = 100 # in meters WORKSPACE = r"C:\Data\MyProject.gdb"
Geodatabase and File Names
Keep these simple and descriptive. Use underscores (_) instead of spaces.
- Good:
parcels_analysis.gdb,2025_Infrastructure_Project.gdb,city_roads.shp - Avoid:
Parcels Analysis.gdb,City Roads.shp
Code Structure and Formatting
Indentation: Use 4 Spaces
Always use 4 spaces for indentation. Do not use tabs, as they can display differently across different text editors and cause errors.
- Good:
for row in arcpy.da.SearchCursor(fc, ["SHAPE@"]): # 4 spaces for the loop block area = row[0].getArea("GEODESIC") if area > 10000: # 8 spaces for the if block print("Large parcel found.")
Line Length: Max 79 or 99 Characters
To ensure readability across different screens and editors, limit lines to 79 characters. For code that will be printed or viewed in a console, 99 characters is a common and acceptable alternative.
- Bad (too long):
arcpy.management.SelectLayerByAttribute(lyr, "NEW_SELECTION", f"\"OWNER_NAME\" = '{some_very_long_owner_name_from_a_database_field}' AND \"PARCEL_ID\" IS NOT NULL") - Good (using parentheses for implicit line continuation):
arcpy.management.SelectLayerByAttribute( lyr, "NEW_SELECTION", f"\"OWNER_NAME\" = '{some_very_long_owner_name_from_a_database_field}' " f"AND \"PARCEL_ID\" IS NOT NULL" )
Whitespace
Use whitespace to improve readability around operators and after commas.
-
Good:
# Around operators result = (a + b) * c # After commas fields = ["OID@", "SHAPE@", "LAND_USE"]
Writing Idiomatic ArcGIS Python Code
This is where ArcGIS-specific best practices come into play.
Import Statements
-
Group imports: Standard library, third-party libraries, and local application imports.
-
Use
arcpyas an alias: This is the universal standard. -
Import specific functions when possible: This can make code clearer and slightly more efficient.
-
Good:
# Standard library import os import datetime # Third-party library import pandas as pd # ArcGIS module import arcpy # Specific function from a module from arcpy import env # Specific function from a toolset from arcpy.management import CreateFeatureclass, AddField
Workspace Management (Crucial!)
Always set the workspace environment. This simplifies paths for many tools.
-
Good:
import arcpy # Define your workspace path once gdb_path = r"C:\Data\MyProject.gdb" arcpy.env.workspace = gdb_path # Now you can just use the name of the dataset arcpy.management.CopyFeatures("Parcels", "Parcels_Backup")
Using arcpy.da Cursors (Modern & Fast)
For iterating through features or tables, always use the arcpy.da module (SearchCursor, UpdateCursor, InsertCursor). It is significantly faster and more memory-efficient than the older arcpy cursors.
-
Good:
import arcpy fc = "Parcels" fields = ["OID@", "SHAPE@AREA"] with arcpy.da.SearchCursor(fc, fields) as cursor: for row in cursor: oid = row[0] area = row[1] print(f"Object ID: {oid}, Area: {area:.2f}") -
Avoid (Older, slower method):
# Don't do this unless you have a specific reason rows = arcpy.SearchCursor(fc, fields) for row in rows: oid = row.getValue("OID@") area = row.getValue("SHAPE@AREA")
Hardcoding Paths is Bad Practice
Avoid putting full paths directly in your tools. Use variables or, even better, allow the user to provide them via command-line arguments.
-
Bad (Hardcoded):
arcpy.management.Buffer("C:\\Data\\Parcels.shp", "C\\Data\\Parcels_Buffer.shp", "100 meters") -
Good (Using variables):
import arcpy input_fc = r"C:\Data\Parcels.shp" output_fc = r"C:\Data\Parcels_Buffer.shp" arcpy.management.Buffer(input_fc, output_fc, "100 meters")
Error Handling: Use try...except
ArcGIS operations can fail for many reasons (e.g., a locked file, a broken network path, invalid data). Always wrap your geoprocessing logic in a try...except block to handle errors gracefully.
-
Good:
import arcpy try: print("Starting buffer operation...") arcpy.management.Buffer("Parcels", "Parcels_Buffer", "500 feet") print("Buffer completed successfully!") except arcpy.ExecuteError: # Handle ArcGIS specific errors print("ArcGIS Tool Error:") print(arcpy.GetMessages(2)) # Print error messages except Exception as e: # Handle any other unexpected errors print(f("An unexpected error occurred: {e}"))
Documentation and Comments
Docstrings for Functions and Scripts
Use triple-quoted strings ("""Docstring""") to document what your functions or entire scripts do. A good docstring includes:
-
A one-line summary.
-
A more detailed description.
-
Information about arguments (
Args:). -
Information about what is returned (
Returns:). -
Good:
import arcpy def buffer_features(input_fc, output_fc, distance): """ Buffers a feature class by a specified distance. Args: input_fc (str): Path to the input feature class. output_fc (str): Path to the output feature class. distance (str): The buffer distance (e.g., "100 meters"). Returns: str: Path to the created output feature class. """ arcpy.management.Buffer(input_fc, output_fc, distance) return output_fc # For a standalone script, a "header" docstring is useful """ ----------------------------------------------------------------------------- Script: BufferParcels.py Author: Your Name Date: 2025-10-27 Description: This script buffers all parcel features in a geodatabase by 500 feet and saves the result to a new feature class. Usage: BufferParcels.py ----------------------------------------------------------------------------- """
Inline Comments for Complex Logic
Don't comment on obvious things. Comment on the why, not the what.
- Bad (Commenting the obvious):
# This is a for loop for row in cursor: # This gets the OID oid = row[0] - Good (Commenting the intent):
# Filter for parcels larger than 1 acre to reduce processing time with arcpy.da.SearchCursor("Parcels", ["OID@", "SHAPE@AREA"]) as cursor: for row in cursor: # Area is in square meters; 1 acre = 4046.86 sq meters if row[1] > 4046.86: # ... process large parcel pass
Putting It All Together: A Complete Example
Here is a script that incorporates many of these principles.
# -----------------------------------------------------------------------------
# Script: CreateAndBufferParcels.py
# Author: Your Name
# Date: 2025-10-27
# Description: Creates a new point feature class from an address table,
# geocodes the addresses, and buffers the points.
# Usage: CreateAndBufferParcels.py
# -----------------------------------------------------------------------------
import arcpy
import os
# --- Configuration ---
# Use constants for values that might change
WORKSPACE = r"C:\Data\Project.gdb"
ADDRESS_TABLE = "Addresses.csv"
OUTPUT_POINTS = "GeocodedAddresses"
BUFFER_DISTANCE = "500 feet"
OUTPUT_BUFFER = "AddressPoints_Buffer"
def main():
"""
Main execution function for the script.
"""
try:
# Set environment settings
arcpy.env.workspace = WORKSPACE
arcpy.env.overwriteOutput = True # Useful for development
print("Starting geocoding process...")
# Step 1: Create a point feature class from an address table
# Use descriptive variable names
address_fields = ["Address", "City"]
xy_fields = ["Address", "City"]
arcpy.management.XYTableToPoint(
ADDRESS_TABLE,
OUTPUT_POINTS,
"Address", # X field
"City", # Y field (optional if addresses are complete)
coordinate_system=arcpy.SpatialReference(26910) # NAD_1983_UTM_Zone_10N
)
print(f"Successfully created point feature class: {OUTPUT_POINTS}")
# Step 2: Buffer the new points
print(f"Buffering points by {BUFFER_DISTANCE}...")
arcpy.management.Buffer(
in_features=OUTPUT_POINTS,
out_feature_class=OUTPUT_BUFFER,
buffer_distance_or_field=BUFFER_DISTANCE
)
print(f"Buffering complete. Output saved to: {OUTPUT_BUFFER}")
print("\nScript finished successfully!")
except arcpy.ExecuteError:
# Handle errors from ArcGIS tools
print("\n--- ARCGIS TOOL ERROR ---")
print(arcpy.GetMessages(2))
except Exception as e:
# Handle any other unexpected errors
print(f"\n--- UNEXPECTED ERROR ---")
print(f"An error occurred: {e}")
if __name__ == "__main__":
# This ensures the main() function is called only when the script
# is executed directly, not when imported as a module.
main()