Of course! Here is a comprehensive guide to using the AdamOptimizer in Python, covering the theory, implementation with TensorFlow, and a complete runnable example.

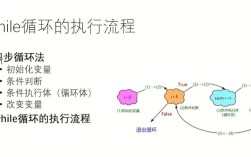
What is Adam?
Adam (short for Adaptive Moment Estimation) is a highly popular and effective optimization algorithm used in training deep learning models. It's an extension of the stochastic gradient descent (SGD) algorithm that combines ideas from two other extensions: RMSprop and Momentum.
Key Concepts: How Adam Works
Adam maintains two moving averages for each parameter in your model:
- First Moment (Mean) -
m_t: This is an estimate of the gradient's mean (like momentum). It helps accelerate the gradient descent in the relevant direction and dampens oscillations. - Second Moment (Uncentered Variance) -
v_t: This is an estimate of the gradient's uncentered variance (like RMSprop). It adapts the learning rate for each parameter, scaling it down for parameters with large gradients and scaling it up for parameters with small gradients.
Adam calculates these two moving averages and then uses them to update the model's parameters. It also includes a bias correction step, as the initial estimates of the moments are biased towards zero.
Why is it so popular?

- Adaptive Learning Rate: It automatically adjusts the learning rate for each parameter, which is very effective for problems with sparse gradients or noisy data.
- Fast Convergence: It often converges much faster than standard SGD.
- Robustness: It's generally robust to the choice of the initial learning rate, making it easier to use in practice.
Implementation with TensorFlow
In modern TensorFlow (version 2.x and later), the AdamOptimizer is part of the high-level Keras API, which is the recommended way to build and train models.
Setup
First, make sure you have TensorFlow installed:
pip install tensorflow
Importing the Optimizer
You import the Adam optimizer from tensorflow.keras.optimizers.
import tensorflow as tf from tensorflow.keras.optimizers import Adam
Creating the Optimizer
When you create the optimizer, you can specify its hyperparameters. The most important one is the learning rate.

# Create an Adam optimizer with a learning rate of 0.001 # This is the default and most common learning rate. optimizer = Adam(learning_rate=0.001)
Common Hyperparameters:
learning_rate(float): The step size at each iteration. Default is001.beta_1(float): The exponential decay rate for the 1st moment estimates (momentum). Default is9.beta_2(float): The exponential decay rate for the 2nd moment estimates. Default is999.epsilon(float): A small constant for numerical stability to prevent division by zero. Default is1e-7.
Using the Optimizer in a Model
You typically pass the optimizer when you compile your Keras model.
Let's create a simple neural network to classify handwritten digits from the MNIST dataset.
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.optimizers import Adam
# 1. Load and prepare the data
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0 # Normalize pixel values to [0, 1]
# 2. Build the model
model = Sequential([
Flatten(input_shape=(28, 28)), # Flatten the 28x28 images to a 784-dimensional vector
Dense(128, activation='relu'), # A fully connected layer with 128 neurons
Dense(10, activation='softmax') # Output layer with 10 neurons (one for each digit)
])
# 3. Compile the model with the Adam optimizer
# We specify the optimizer, the loss function, and the metrics to monitor.
model.compile(optimizer=Adam(learning_rate=0.001),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 4. Train the model
print("Training the model...")
history = model.fit(x_train, y_train, epochs=5, validation_split=0.2)
# 5. Evaluate the model
print("\nEvaluating the model...")
loss, accuracy = model.evaluate(x_test, y_test)
print(f"Test Accuracy: {accuracy:.4f}")
Using the Optimizer Manually (Advanced)
For more complex training loops or custom research, you might want to use the optimizer directly. This involves calculating gradients and applying them manually.
Here's a conceptual example of how you would do this:
import tensorflow as tf
# 1. Define a simple model (e.g., a single linear layer)
model = tf.keras.Sequential([tf.keras.layers.Dense(units=1, input_shape=[1])])
# 2. Define the optimizer
optimizer = tf.keras.optimizers.Adam(learning_rate=0.1)
# 3. Define a loss function
loss_fn = tf.keras.losses.MeanSquaredError()
# 4. Create some data (y = 2x + 1)
x_train = tf.constant([-1.0, 0.0, 1.0, 2.0, 3.0, 4.0], dtype=tf.float32)
y_train = tf.constant([-1.0, 1.0, 3.0, 5.0, 7.0, 9.0], dtype=tf.float32)
# 5. Training loop
epochs = 200
for epoch in range(epochs):
with tf.GradientTape() as tape:
# Forward pass: compute the model's prediction
predictions = model(x_train, training=True)
# Compute the loss
loss = loss_fn(y_train, predictions)
# Compute gradients
gradients = tape.gradient(loss, model.trainable_variables)
# Apply gradients to update the model's weights
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
# Print the loss every 50 epochs
if epoch % 50 == 0:
print(f"Epoch {epoch}, Loss: {loss.numpy()}")
# Check the learned weights
print("\nLearned weights:")
for var in model.trainable_variables:
print(f"{var.name}: {var.numpy()}")
# Expected weights should be close to w=2 and b=1
Complete Runnable Example
Here is a full, self-contained script that trains a model on the MNIST dataset using the Adam optimizer.
import tensorflow as tf
from tensorflow.keras import layers, models, datasets, optimizers
import matplotlib.pyplot as plt
# 1. Load and preprocess the MNIST dataset
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()
# Normalize pixel values to be between 0 and 1
train_images, test_images = train_images / 255.0, test_images / 255.0
# 2. Build the Convolutional Neural Network (CNN)
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(10, activation='softmax')
])
# 3. Compile the model
# Here we instantiate and use the Adam optimizer
adam_optimizer = optimizers.Adam(learning_rate=0.001)
model.compile(optimizer=adam_optimizer,
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# Print model summary
model.summary()
# 4. Train the model
print("\n--- Starting Training ---")
history = model.fit(train_images, train_labels, epochs=5,
validation_data=(test_images, test_labels))
# 5. Evaluate the model on the test set
print("\n--- Evaluating Model ---")
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print(f"\nTest accuracy: {test_acc:.4f}")
# 6. (Optional) Plot training & validation accuracy values
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])'Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
# Plot training & validation loss values
plt.subplot(1, 2, 2)
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])'Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
Summary
| Feature | Description | | :--- |