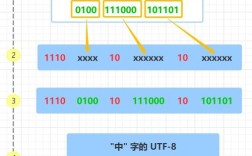
在 Python 3 中,字符串(str)类型本身就是 Unicode 字符串,你不需要也不应该将一个 UTF-8 编码的字符串“转换”成 Unicode,因为它们本质上是一回事。

(图片来源网络,侵删)
你真正需要做的是在两种表示形式之间进行转换:
- Unicode 字符串:Python 内部使用的格式,人类可读。
"你好"。 - 字节串:内存或文件中实际存储数据的格式,是 Unicode 经过某种编码(如 UTF-8)后的二进制表示。
b'\xe4\xbd\xa0\xe5\xa5\xbd'。
你问的“UTF-8 转 Unicode”,在 Python 3 中通常指的是 “将 UTF-8 编码的字节串解码(Decode)成 Unicode 字符串”。
核心概念:编码与解码
- 编码:将 Unicode 字符串转换为字节串的过程。
"你好"->b'\xe4\xbd\xa0\xe5\xa5\xbd'(使用 UTF-8 编码)
- 解码:将字节串转换回 Unicode 字符串的过程。
b'\xe4\xbd\xa0\xe5\xa5\xbd'->"你好"(使用 UTF-8 解码)
将 UTF-8 字节串解码为 Unicode 字符串 (最常见的需求)
假设你从文件、网络或其他地方读取到了一段用 UTF-8 编码的二进制数据,它是一个字节串对象(bytes),你需要把它变成可以正常处理的字符串(str)。
方法:使用 bytes 对象的 .decode() 方法

(图片来源网络,侵删)
# 1. 定义一个 UTF-8 编码的字节串
# 注意:这是 bytes 类型,前面有 b''
utf8_bytes = b'\xe4\xbd\xa0\xe5\xa5\xbd' # 这是 "你好" 的 UTF-8 编码
# 2. 将字节串解码为 Unicode 字符串
# 我们告诉 .decode() 方法,这个字节串是用 'utf-8' 编码的
unicode_str = utf8_bytes.decode('utf-8')
# 3. 验证结果
print(f"原始字节串: {utf8_bytes}")
print(f"解码后的字符串: {unicode_str}")
print(f"字符串类型: {type(unicode_str)}")
# 你可以像操作普通字符串一样操作它
print(f"字符串长度: {len(unicode_str)}") # 输出 2,因为有两个中文字符
print(f"第一个字符: {unicode_str[0]}") # 输出 你
输出:
原始字节串: b'\xe4\xbd\xa0\xe5\xa5\xbd'
解码后的字符串: 你好
字符串类型: <class 'str'>
字符串长度: 2
第一个字符: 你处理解码错误
如果字节串不是有效的 UTF-8 编码,.decode() 会抛出 UnicodeDecodeError,你可以使用 errors 参数来处理这种情况。
errors='strict'(默认):遇到错误直接抛出异常。errors='ignore':忽略无法解码的字节。errors='replace':将无法解码的字节替换成一个占位符(通常是 �)。
# 创建一个包含无效 UTF-8 字节的字节串
invalid_bytes = b'\xe4\xbd\xa0\xff\xfe\xa5\xbd'
# 1. 使用 strict 模式 (默认),会报错
try:
invalid_bytes.decode('utf-8')
except UnicodeDecodeError as e:
print(f"Strict 模式下出错: {e}")
# 2. 使用 ignore 模式,直接丢弃无效字节
ignored_str = invalid_bytes.decode('utf-8', errors='ignore')
print(f"Ignore 模式结果: {ignored_str}") # 输出 "你好"
# 3. 使用 replace 模式,用 � 替换无效字节
replaced_str = invalid_bytes.decode('utf-8', errors='replace')
print(f"Replace 模式结果: {replaced_str}") # 输出 "你好��"
将 Unicode 字符串编码为 UTF-8 字节串
这是上述过程的反向操作,当你需要将字符串写入文件或通过网络发送时,就需要进行编码。
方法:使用 str 对象的 .encode() 方法

(图片来源网络,侵删)
# 1. 定义一个 Unicode 字符串
# 这是 Python 3 中最常用的字符串类型
unicode_str = "你好,世界!"
# 2. 将字符串编码为 UTF-8 字节串
# 我们告诉 .encode() 方法,希望它被编码成 'utf-8' 格式
utf8_bytes = unicode_str.encode('utf-8')
# 3. 验证结果
print(f"原始字符串: {unicode_str}")
print(f"编码后的字节串: {utf8_bytes}")
print(f"字节串类型: {type(utf8_bytes)}")
输出:
原始字符串: 你好,世界!
编码后的字节串: b'\xe4\xbd\xa0\xe5\xa5\xbd\xef\xbc\x8c\xe4\xb8\x96\xe7\x95\x8c\xef\xbc\x81'
字节串类型: <class 'bytes'>文件读写中的编码处理
在实际应用中,最常见的就是读写文件,Python 的 open() 函数有一个 encoding 参数,可以让你轻松地处理编码。
写入文件 (编码)
content = "这是一段用 UTF-8 编码的文字。"
# 使用 'w' 模式打开文件,并指定 encoding='utf-8'
# Python 会自动将字符串 content 编码成 UTF-8 格式再写入
with open('my_file.txt', 'w', encoding='utf-8') as f:
f.write(content)
print("文件写入成功。")
读取文件 (解码)
# 使用 'r' 模式打开文件,并指定 encoding='utf-8'
# Python 会自动从文件中读取字节流,并将其解码成 UTF-8 字符串
with open('my_file.txt', 'r', encoding='utf-8') as f:
read_content = f.read()
print(f"从文件读取的内容: {read_content}")
print(f"内容类型: {type(read_content)}")
总结与常见误区
| 操作 | Python 3 代码 | 说明 |
|---|---|---|
| UTF-8 -> Unicode | my_bytes.decode('utf-8') |
将字节串解码为字符串,这是对“二进制数据”的操作。 |
| Unicode -> UTF-8 | my_str.encode('utf-8') |
将字符串编码为字节串,这是准备“存储或传输”数据。 |
| 读取 UTF-8 文件 | open('file.txt', 'r', encoding='utf-8').read() |
open 函数自动处理解码。 |
| 写入 UTF-8 文件 | open('file.txt', 'w', encoding='utf-8').write(my_str) |
open 函数自动处理编码。 |
常见误区:
-
误区:认为 Python 3 的
str和bytes是一回事。- 事实:它们是两种完全不同的类型。
str是抽象的字符序列,bytes是原始的字节序列,必须通过编码和解码在两者之间转换。
- 事实:它们是两种完全不同的类型。
-
误区:在
open()函数中不指定encoding。- 事实:在 Python 3 中,如果你不指定
encoding,它会使用系统的默认编码(在 Windows 上通常是cp936,在 Linux/macOS 上通常是UTF-8),这可能导致在不同系统上程序行为不一致,或者读取非 UTF-8 文件时出错。最佳实践是始终显式指定encoding。
- 事实:在 Python 3 中,如果你不指定
-
误区:在 Python 2 中思考问题。
- 在 Python 2 中,
str类型是字节串,unicode类型才是 Unicode 字符串,两者之间的转换非常频繁且容易出错,Python 3 从根本上解决了这个问题,使得处理文本和二进制数据更加清晰,如果你还在用 Python 2,请尽快升级。
- 在 Python 2 中,