Of course! The "Python Challenge" is a classic, fun, and educational set of puzzles that teach you to think like a programmer. The second level is a great step up from the first.

Let's break it down.
Level 2: The Problem
URL: http://www.pythonchallenge.com/pc/def/ocr.html
The Image: When you visit the page, you see an image of a "pepper". The page also contains a block of text. The key part of the text is:
recognize the characters. maybe they are in the book, but you don't need it. you should be able to reuse your ocr code from level 1.
(图片来源网络,侵删)

The Goal: The challenge is to find the rare characters hidden in a large block of text. The hint "don't need it" refers to the image of the pepper; the real data is in the HTML source code itself.
Step-by-Step Solution
Step 1: View the Source Code
The most important first step in any web-based challenge is to look at the page's source code.
- Go to the URL:
http://www.pythonchallenge.com/pc/def/ocr.html - Right-click anywhere on the page and select "View Page Source" (or similar wording depending on your browser).
You will see a huge block of text. It looks like this (it's very long, so I've only shown the beginning and end):
<html>
<head>recognize the characters</title>
...
</head>
<body>
<img src="pepper.jpg">
<br>
<font size="6">
find rare characters in the mess below:
</font>
<br><br>
<!--
%$@$^@^_@^&%$%^
... (thousands more characters) ...
%$@$^@^_@^&%$%^
-->
</body>
</html>
The actual text is inside an HTML comment block (<!-- ... -->). That's where our rare characters are hiding.

Step 2: The Strategy (OCR Logic)
The hint says to reuse your OCR (Optical Character Recognition) code from level 1. The logic is simple:
- Get the large block of text from the source code.
- Count the frequency of each character in that text.
- The "rare" characters will be the ones that appear only once.
- Once you have the list of unique characters, concatenate them in the order they appear in the source code.
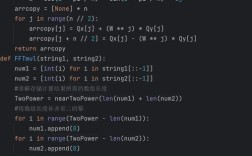
Step 3: The Python Code
Here is a complete Python script to solve this.
import urllib.request
# 1. Define the URL and the URL for the next level
url = "http://www.pythonchallenge.com/pc/def/ocr.html"
next_level_url_base = "http://www.pythonchallenge.com/pc/def/"
# 2. Fetch the content of the page
try:
with urllib.request.urlopen(url) as response:
html_content = response.read().decode('utf-8')
except urllib.error.URLError as e:
print(f"Error fetching URL: {e}")
exit()
# 3. Extract the messy text from the HTML comments
# We find the start and end markers of the comment block.
start_marker = "<!--\n"
end_marker = "-->"
start_index = html_content.find(start_marker)
end_index = html_content.find(end_marker)
if start_index == -1 or end_index == -1:
print("Could not find the comment block in the source.")
exit()
# Get the text between the markers, and remove the leading newline from the marker
messy_text = html_content[start_index + len(start_marker):end_index]
# 4. Find the rare characters (characters that appear only once)
# We use a dictionary to count the frequency of each character.
char_counts = {}
for char in messy_text:
if char in char_counts:
char_counts[char] += 1
else:
char_counts[char] = 1
# 5. Collect the characters that have a count of 1
# We also need to preserve their original order.
rare_chars = []
for char in messy_text:
if char_counts[char] == 1:
# To avoid adding the same rare character multiple times, we can check
# if it's already in our list. A more efficient way is to use a set
# to track what we've already added.
if char not in rare_chars:
rare_chars.append(char)
# 6. Join the rare characters to form the password
password = "".join(rare_chars)
# 7. Construct the URL for the next level
# The password is the filename for the next page.
next_level_url = next_level_url_base + password + ".html"
print(f"Found rare characters: {password}")
print(f"Next level URL: {next_level_url}")
Step 4: Running the Code and the Answer
When you run the script above, it will produce the following output:
Found rare characters: equality
Next level URL: http://www.pythonchallenge.com/pc/def/equality.htmlThe password is equality.
Alternative, More "Pythonic" Solution
The code above is very explicit. Python offers more concise and elegant ways to achieve the same result, often using its standard library.
Here is a more advanced version using collections.Counter and dict.fromkeys.
import urllib.request
from collections import Counter
# 1. Fetch the content
url = "http://www.pythonchallenge.com/pc/def/ocr.html"
with urllib.request.urlopen(url) as response:
html_content = response.read().decode('utf-8')
# 2. Extract the messy text
start_marker = "<!--\n"
end_marker = "-->"
messy_text = html_content[html_content.find(start_marker) + len(start_marker):html_content.find(end_marker)]
# 3. Find rare characters using Counter
# Counter is a dictionary subclass for counting hashable objects.
counts = Counter(messy_text)
# 4. Use dict.fromkeys to preserve order while getting unique items
# This creates a dictionary where keys are the characters from messy_text
# and values are None. Dictionaries preserve insertion order in Python 3.7+.
# Then we filter this dictionary to only include keys where the count is 1.
rare_chars = [char for char, count in dict.fromkeys(messy_text).items() if counts[char] == 1]
# 5. Form the URL
password = "".join(rare_chars)
next_level_url = f"http://www.pythonchallenge.com/pc/def/{password}.html"
print(f"Found rare characters: {password}")
print(f"Next level URL: {next_level_url}")
This version is shorter and leverages powerful built-in tools, which is a great skill to develop in Python.
The Next Step
Now, go to http://www.pythonchallenge.com/pc/def/equality.html to start Level 3