Python数据处理库大全
我们可以将这些库大致分为几个类别:

(图片来源网络,侵删)
- 核心基础库: 数据处理的地基,特别是NumPy和Pandas。
- 数据可视化库: 让数据“开口说话”。
- 科学计算与统计分析库: 更深入的建模和分析。
- 数据库与大数据连接库: 连接外部数据源。
- 其他实用工具库: 提升数据准备和处理的效率。
核心基础库
这是数据科学家的“武器库”中最核心的部分,几乎所有的数据分析流程都离不开它们。
NumPy (Numerical Python)
- 一句话介绍: Python科学计算的基础包,提供了高性能的多维数组对象 (
ndarray)。 - 核心功能:
- 多维数组对象: 这是其核心,提供了比Python原生列表高效得多的数据结构。
- 数学函数: 提供了大量的数学函数,可以对数组进行元素级运算(如三角函数、指数、对数等)。
- 线性代数: 强大的矩阵运算功能,如点积、矩阵乘法、求逆、特征值分解等。
- 随机数生成: 可以生成各种分布的随机数。
- 为什么重要: Pandas和许多其他库都构建在NumPy之上,NumPy的数组操作是高性能科学计算的基石。
- 典型应用场景: 数值计算、算法实现、作为其他库的底层数据结构。
Pandas
- 一句话介绍: 基于NumPy构建,提供了DataFrame和Series两种数据结构,是Python数据分析的“瑞士军刀”。
- 核心功能:
- DataFrame: 一个二维的、带标签的、大小可变的表格型数据结构,类似于Excel或SQL表。
- Series: 一维的、带标签的数组,是DataFrame的列。
- 数据清洗: 处缺失值 (
fillna(),dropna())、重复值 (drop_duplicates())、数据类型转换 (astype())。 - 数据筛选与查询:
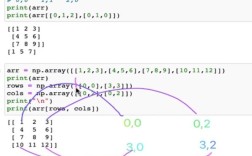
.loc(基于标签) 和.iloc(基于整数位置) 进行精确的数据切片和切块。 - 数据合并与连接:
pd.concat(),pd.merge(),pd.join()实现类似SQL的表连接操作。 - 分组聚合:
groupby()是其最强大的功能之一,可以实现“Split-Apply-Combine”操作。 - 时间序列处理: 专门为处理时间序列数据而设计,功能非常强大。
- 为什么重要: 它极大地简化了数据加载、清洗、转换、分析和可视化等任务,让数据分析师可以像使用Excel一样直观地操作数据,但性能和灵活性远超Excel。
- 典型应用场景: 几乎所有的数据分析任务,如读取CSV/Excel文件、数据清洗、探索性数据分析、特征工程等。
SciPy (Scientific Python)
- 一句话介绍: 在NumPy的基础上构建,提供了更高级的科学计算功能。
- 核心功能:
- 积分:
scipy.integrate - 优化:
scipy.optimize(如寻找最小值、拟合曲线) - 线性代数:
scipy.linalg(比NumPy更高级) - 统计:
scipy.stats(提供了大量的概率分布和统计检验函数) - 信号处理:
scipy.signal - 图像处理:
scipy.ndimage
- 积分:
- 为什么重要: 当NumPy无法满足更复杂的科学计算需求时,SciPy是下一个选择。
- 典型应用场景: 科学和工程领域的复杂计算、统计分析、模型优化。
数据可视化库
数据可视化是理解数据、发现洞察的关键一步。
Matplotlib
- 一句话介绍: Python最基础、最经典的绘图库,功能强大但语法略显繁琐。
- 核心功能:
- 高度可定制: 可以控制图表的几乎所有元素(坐标轴、标题、标签、图例、颜色、线型等)。
- 支持多种图表类型: 折线图、散点图、柱状图、直方图、饼图、箱线图等。
- 为什么重要: 它是许多高级可视化库(如Seaborn、Pandas内置绘图)的底层引擎,理解Matplotlib有助于你更好地定制和调试更复杂的图表。
- 典型应用场景: 创建高质量的静态图表,用于学术报告、数据分析报告。
Seaborn
- 一句话介绍: 基于Matplotlib构建,提供了更美观、更高级的统计图形接口。
- 核心功能:
- 美观的默认样式: 图表通常比Matplotlib更漂亮。
- 统计图表: 专门为数据可视化而生,提供了如热力图、分布图、小提琴图、成对关系图等高级统计图表。
- 与Pandas无缝集成: 可以直接接受Pandas的DataFrame作为输入。
- 为什么重要: 用更少的代码就能创建出信息丰富、视觉吸引力强的图表,特别适合探索性数据分析。
- 典型应用场景: 快速绘制多变量关系、分布、分类统计图表。
Plotly / Dash
- 一句话介绍: 用于创建交互式图表和Web应用程序的库。
- 核心功能:
- 交互性: 用户可以缩放、平移、悬停查看数据点详情。
- 丰富的图表类型: 支持各种3D图表、地理空间图表等。
- Dash: 一个基于Plotly的Web应用框架,可以轻松将数据分析和可视化结果打包成一个可交互的Web应用。
- 为什么重要: 将数据分析从静态报告推向了动态交互,非常适合制作数据仪表盘。
- 典型应用场景: 构建数据仪表盘、创建交互式报告和Web应用。
科学计算与统计分析库
当你需要从数据中建模、预测和得出统计结论时,这些库就派上用场了。
Scikit-learn
- 一句话介绍: Python中最流行的机器学习库,提供了简单高效的工具用于数据挖掘和数据分析。
- 核心功能:
- **分类逻辑回归、支持向量机、决策树、随机森林、K-NN等。
- 回归: 线性回归、岭回归、Lasso回归等。
- 聚类: K-Means、DBSCAN等。
- 降维: PCA (主成分分析)、t-SNE等。
- 模型评估与选择: 交叉验证、网格搜索、各种评估指标。
- 为什么重要: 它的API设计非常一致、简洁,所有算法都遵循
fit(),predict(),transform()的模式,学习曲线平缓,是入门机器学习的首选。 - 典型应用场景: 几乎所有的传统机器学习任务,如客户流失预测、垃圾邮件识别、图像分类等。
Statsmodels
- 一句话介绍: 专注于统计建模和计量经济学的库,提供了更详尽的统计检验结果。
- 核心功能:
- 线性回归模型: 提供了比Scikit-learn更丰富的模型摘要,如R²、Adj. R²、F-statistic、AIC、BIC等。
- 时间序列分析: ARIMA、VAR等模型。
- 统计检验: t检验、卡方检验、方差分析等。
- 为什么重要: 如果你需要进行严谨的统计推断(而不仅仅是预测),Statsmodels是更好的选择,它提供了Scikit-learn所不具备的统计细节。
- 典型应用场景: 经济数据分析、A/B测试结果分析、需要严格统计推断的场景。
数据库与大数据连接库
数据通常存储在数据库或大数据平台中,Python需要工具来连接它们。

(图片来源网络,侵删)
SQLAlchemy
- 一句话介绍: Python SQL工具包和对象关系映射器,提供了强大的SQL数据库交互能力。
- 核心功能:
- SQL表达式语言: 允许你用Python代码构建SQL查询,而不是手写字符串,更安全、更灵活。
- ORM (Object-Relational Mapping): 将数据库表映射为Python类,将行映射为对象,可以用面向对象的方式操作数据库。
- 为什么重要: 它是Python连接关系型数据库的“标准”方式,支持多种数据库(MySQL, PostgreSQL, SQLite等),并且是Pandas
read_sql()函数的推荐后端。
Dask
- 一句话介绍: 用于并行计算的灵活库,可以“扩展”Pandas和NumPy以处理大于内存的数据集。
- **核心功能

(图片来源网络,侵删)