XPath 是一门在 XML 文档中查找信息的语言,它通过路径表达式来选取 XML 文档中的节点或节点集,Java 标准库 javax.xml.xpath 提供了完整的 XPath 支持。

下面我将从基础到高级,通过完整的示例代码,为你演示如何使用 XPath。
准备工作:XML 示例文件
我们创建一个示例 XML 文件 students.xml,后续的所有操作都将基于这个文件。
students.xml
<?xml version="1.0" encoding="UTF-8"?>
<class>
<student id="001">
<name>Alice</name>
<age>20</age>
<gender>Female</gender>
<courses>
<course name="Math" score="95"/>
<course name="Physics" score="88"/>
</courses>
</student>
<student id="002">
<name>Bob</name>
<age>22</age>
<gender>Male</gender>
<courses>
<course name="History" score="92"/>
<course name="Literature" score="85"/>
</courses>
</student>
<student id="003">
<name>Charlie</name>
<age>21</age>
<gender>Male</gender>
<courses>
<course name="Math" score="90"/>
<course name="Chemistry" score="78"/>
</courses>
</student>
</class>
基本步骤
在 Java 中使用 XPath 通常遵循以下三个步骤:

- 获取
XPathFactory实例:这是创建 XPath 处理器的工厂。 - 创建
XPath对象:通过工厂对象创建XPath实例,它将用于编译和评估 XPath 表达式。 - 编译 XPath 表达式并评估:使用
XPath对象的compile()方法编译表达式,然后用evaluate()方法在 XML 文档上执行该表达式。
完整示例代码
下面是一个完整的 Java 类,演示了如何读取 students.xml 并执行各种 XPath 查询。
XPathParserDemo.java
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.xpath.XPath;
import javax.xml.xpath.XPathConstants;
import javax.xml.xpath.XPathExpression;
import javax.xml.xpath.XPathExpressionException;
import javax.xml.xpath.XPathFactory;
import org.w3c.dom.Document;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.InputSource;
import java.io.File;
public class XPathParserDemo {
public static void main(String[] args) {
try {
// 1. 创建 XPathFactory 和 XPath 对象
XPathFactory xPathFactory = XPathFactory.newInstance();
XPath xpath = xPathFactory.newXPath();
// 2. 加载 XML 文档到 DOM (Document Object Model)
// XPath 通常需要一个 DOM Document 或 InputSource 作为输入
File xmlFile = new File("students.xml");
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder db = dbf.newDocumentBuilder();
Document document = db.parse(xmlFile);
// --- 示例 1: 获取单个节点的文本内容 ---
// 获取第一个学生的名字
String studentName = (String) xpath.evaluate("/class/student[1]/name/text()", document, XPathConstants.STRING);
System.out.println("1. 第一个学生的名字: " + studentName); // 输出: Alice
// --- 示例 2: 获取属性值 ---
// 获取第二个学生的 id 属性
String studentId = (String) xpath.evaluate("/class/student[2]/@id", document, XPathConstants.STRING);
System.out.println("2. 第二个学生的ID: " + studentId); // 输出: 002
// --- 示例 3: 获取节点列表 ---
// 获取所有学生的名字
NodeList nameNodes = (NodeList) xpath.evaluate("/class/student/name", document, XPathConstants.NODESET);
System.out.println("3. 所有学生的名字:");
for (int i = 0; i < nameNodes.getLength(); i++) {
System.out.println(" - " + nameNodes.item(i).getTextContent());
}
/* 输出:
3. 所有学生的名字:
- Alice
- Bob
- Charlie
*/
// --- 示例 4: 使用谓词 (Predicates) 进行条件查询 ---
// 获取所有年龄大于21岁的学生
NodeList olderStudents = (NodeList) xpath.evaluate("/class/student[age > 21]", document, XPathConstants.NODESET);
System.out.println("\n4. 年龄大于21岁的学生数量: " + olderStudents.getLength()); // 输出: 1
for (int i = 0; i < olderStudents.getLength(); i++) {
Node studentNode = olderStudents.item(i);
// 需要在子节点中查找 name
String name = (String) xpath.evaluate("name/text()", studentNode, XPathConstants.STRING);
String age = (String) xpath.evaluate("age/text()", studentNode, XPathConstants.STRING);
System.out.println(" - 姓名: " + name + ", 年龄: " + age);
}
/* 输出:
4. 年龄大于21岁的学生数量: 1
- 姓名: Bob, 年龄: 22
*/
// --- 示例 5: 使用通配符 ---
// 获取第一个学生的所有子元素 (name, age, gender, courses)
NodeList firstStudentChildren = (NodeList) xpath.evaluate("/class/student[1]/*", document, XPathConstants.NODESET);
System.out.println("\n5. 第一个学生的所有子元素:");
for (int i = 0; i < firstStudentChildren.getLength(); i++) {
System.out.println(" - " + firstStudentChildren.item(i).getNodeName());
}
// --- 示例 6: 使用轴 (Axes) ---
// 获取 "Bob" 节点的所有祖先节点 (class, ...)
// ancestor:: 会从当前节点向上查找
System.out.println("\n6. 'Bob' 节点的所有祖先节点:");
NodeList ancestors = (NodeList) xpath.evaluate("student[name='Bob']/ancestor::*", document, XPathConstants.NODESET);
for (int i = 0; i < ancestors.getLength(); i++) {
System.out.println(" - " + ancestors.item(i).getNodeName());
}
/* 输出:
6. 'Bob' 节点的所有祖先节点:
- class
*/
// --- 示例 7: 使用函数 ---
// 获取学生总数 (count 函数)
// 注意:XPath 1.0 没有内置的 sum 函数对数字求和,但 count 可以
Double studentCount = (Double) xpath.evaluate("count(/class/student)", document, XPathConstants.NUMBER);
System.out.println("\n7. 学生总数: " + studentCount.intValue()); // 输出: 3
// --- 示例 8: 复杂查询 - 获取所有选修了 Math 课的学生 ---
// 使用 contains 或 =
System.out.println("\n8. 选修了 Math 课的学生:");
NodeList mathStudents = (NodeList) xpath.evaluate("/class/student[course[@name='Math']]", document, XPathConstants.NODESET);
for (int i = 0; i < mathStudents.getLength(); i++) {
Node studentNode = mathStudents.item(i);
String name = (String) xpath.evaluate("name/text()", studentNode, XPathConstants.STRING);
System.out.println(" - " + name);
}
/* 输出:
8. 选修了 Math 课的学生:
- Alice
- Charlie
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
代码详解
1 核心类和接口
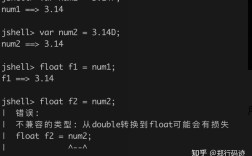
javax.xml.xpath.XPathFactory: 工厂类,用于创建XPath实例。newInstance(): 静态工厂方法,获取默认的XPathFactory实现。
javax.xml.xpath.XPath: 主要接口,用于编译 XPath 表达式和评估表达式。newXPath(): 从XPathFactory获取XPath实例。compile(String expression): 编译一个 XPath 表达式,返回XPathExpression对象,编译可以缓存,提高性能。evaluate(String expression, InputSource source, QName returnType): 执行 XPath 表达式。expression: XPath 字符串。source: XML 源,可以是Document,InputSource等。returnType: 返回值的类型,使用XPathConstants枚举定义。
javax.xml.xpath.XPathConstants: 包含预定义的返回类型常量。XPathConstants.NODE: 返回一个Node。XPathConstants.NODESET: 返回一个NodeList。XPathConstants.STRING: 返回String。XPathConstants.NUMBER: 返回Double。XPathConstants.BOOLEAN: 返回Boolean。
org.w3c.dom.Document: XML 文档在内存中的表示(DOM)。org.w3c.dom.Node: DOM 中任何类型节点的基接口。org.w3c.dom.NodeList: 节点集合,通常用于存储查询结果。
2 关键步骤解析
-
加载 XML:
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); DocumentBuilder db = dbf.newDocumentBuilder(); Document document = db.parse(xmlFile);
这部分代码使用标准的 DOM 解析器将
students.xml文件读入内存,生成一个Document对象。xpath.evaluate()方法可以直接操作这个Document对象。 (图片来源网络,侵删)
(图片来源网络,侵删) -
评估表达式:
// 方式一:直接 evaluate 字符串 String name = (String) xpath.evaluate("/class/student/name", document, XPathConstants.STRING); // 方式二:先编译,再评估(推荐,尤其在循环中) XPathExpression expr = xpath.compile("/class/student/name"); NodeList nodes = (NodeList) expr.evaluate(document, XPathConstants.NODESET);第二种方式(编译后评估)更高效,特别是当同一个 XPath 表达式需要被多次执行时,编译过程会预先解析表达式,后续评估时速度更快。
3 常用 XPath 表达式速查
| 表达式 | 描述 | 示例 |
|---|---|---|
nodename |
选取此节点的所有子节点 | /class/student |
| 从根节点选取 | /class |
|
| 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置 | //student 选取所有 student 元素 |
|
| 选取当前节点 | ./name 选取当前节点的 name 子节点 |
|
| 选取当前节点的父节点 | ../age |
|
| 选取属性 | student/@id 选取 student 元素的 id 属性 |
|
| 匹配任何元素节点 | /class/*/name 选取 class 下任何层级元素的 name 子元素 |
|
[] |
谓词,用于过滤节点 | /class/student[1] (第一个), /class/student[@id='001'] (id属性为001的) |
text() |
选取文本节点 | /class/student/name/text() |
and, or |
逻辑操作 | /class/student[age > 20 and gender='Female'] |
contains(), starts-with() |
字符串函数 | //student[contains(name, 'li')] (名字包含'li'的学生) |
高级主题:命名空间
XML 文件使用了命名空间,XPath 查询会变得更复杂,你需要先注册命名空间前缀。
示例 XML (ns_students.xml)
<school:students xmlns:school="http://www.example.com/school">
<school:student id="004">
<school:name>David</school:name>
</school:student>
</school:students>
查询带命名空间的 XML
// ...
Document document = db.parse(new File("ns_students.xml"));
// 1. 创建 XPath 对象
XPathFactory xPathFactory = XPathFactory.newInstance();
XPath xpath = xPathFactory.newXPath();
// 2. 注册命名空间前缀
// 第一个参数是你在 XPath 表达式中使用的前缀
// 第二个参数是 XML 中定义的命名空间 URI
xpath.setNamespaceContext(new SimpleNamespaceContext("sch", "http://www.example.com/school"));
// 3. 使用带前缀的 XPath 表达式
String name = (String) xpath.evaluate("/sch:students/sch:student/sch:name/text()", document, XPathConstants.STRING);
System.out.println("命名空间查询结果: " + name); // 输出: David
SimpleNamespaceContext 是一个简单的 NamespaceContext 实现,你可以自己实现 NamespaceContext 接口来处理更复杂的命名空间映射。
使用 XPath 解析 XML 在 Java 中是一个非常强大且灵活的技术,它比 DOM 遍历更简洁,比 SAX 更容易定位特定数据,掌握 XPathFactory, XPath, Document 和常用 XPath 表达式是关键,对于大型 XML 文件,可以考虑使用 SAXSource 或 StAXSource 作为 evaluate 方法的输入,以避免将整个文档加载到内存中。