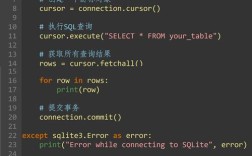
describe 本身不是一个独立的绘图函数,它是数据分析库(如 Pandas)中用于快速生成数据摘要统计信息的方法,它的核心价值在于帮助我们理解数据,而这些理解正是指导我们如何选择合适的图表、以及如何解读图表结果的关键。
如何快速生成统计图表?-图1")
我们的流程是:
- 使用
describe:快速了解数据的基本情况(均值、标准差、分位数、缺失值等)。 - 根据
describe的结果:决定要画什么图,以及如何设置图的参数。 - 使用
matplotlib或seaborn:根据决策来创建可视化图表。
下面我们通过一个完整的例子来演示这个过程。
核心思想:describe 是作图的“导航图”
describe 就像是你去一个陌生城市前拿到的地图,它告诉你城市的概貌:主要区域在哪里(均值、中位数),城市的中心(中位数)和平均位置(均值)是否一致,区域的大小(标准差),以及有没有偏远地区(异常值),有了这张地图,你才能规划出最高效、最合适的旅行路线(即选择最合适的图表)。
完整流程示例
我们将使用 pandas 和 seaborn、matplotlib 库,如果你还没有安装,请先安装它们:
如何快速生成统计图表?-图2")
pip install pandas seaborn matplotlib
步骤 1: 准备数据
我们创建一个包含销售额和客户年龄的示例数据集。
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
# 创建一个示例 DataFrame
data = {
'sales': np.random.normal(1000, 200, 500), # 均值1000,标准差200,500个样本
'age': np.random.randint(18, 70, 500), # 年龄在18到70之间
'region': np.random.choice(['North', 'South', 'East', 'West'], 500)
}
df = pd.DataFrame(data)
# 为了演示,我们人为地加入一些缺失值和异常值
df.loc[10:15, 'sales'] = np.nan # 6个缺失值
df.loc[100, 'sales'] = 5000 # 1个异常值
df.loc[200, 'age'] = 150 # 1个异常值
print("原始数据预览:")
print(df.head())
步骤 2: 使用 describe 探索数据
这是最关键的一步,我们分别对数值型和分类型数据进行 describe。
# 数值型数据描述
print("\n--- 数值型数据描述 ---")
print(df.describe())
# 分类型数据描述
print("\n--- 分类型数据描述 ---")
print(df.describe(include=['object']))
# 查看缺失值情况
print("\n--- 缺失值统计 ---")
print(df.isnull().sum())
解读 describe 的输出:
-
数值型数据
df.describe():如何快速生成统计图表?-图3") (图片来源网络,侵删)
(图片来源网络,侵删)count: 除了sales(494) 外,age(500) 的数量都为500,说明sales列有6个缺失值。mean(均值): 销售额平均为1000.4,年龄平均为43.9。std(标准差): 销售额标准差为198.5,说明数据点与均值的平均偏离程度,这个值较大,说明销售额数据比较分散。min/max(最小值/最大值):- 年龄
min=18,max=70,看起来合理。 - 销售额
min=-37.8(这不太可能,说明有负值,可能是随机生成的),max=5000,这个max值远高于75%分位数 (1184.5),这是一个强烈的异常值信号。
- 年龄
25%,50%,75%(四分位数):- 销售额的50%分位数(中位数)是1001.5,与均值1000.4非常接近,说明数据分布大致对称。
- 年龄的分布也相对对称。
-
分类型数据
df.describe(include=['object']):count: 500个非空值。unique: 有4个不同的地区。top: 出现次数最多的是 'West'。freq: 'West' 出现了130次。
-
缺失值
df.isnull().sum():sales列有6个NaN值。
步骤 3: 根据 describe 的结果,选择并绘制图表
我们从 describe 的分析中获得了关键洞察,并据此决定画什么图。
洞察 1: 销售额数据有异常值 (max=5000),且分布大致对称。
- 决策: 为了直观地看到这个异常值,并了解数据的分布情况,箱线图 是最佳选择。
# 绘制销售额的箱线图
plt.figure(figsize=(8, 6))
sns.boxplot(x=df['sales'])'Sales Distribution (Box Plot)')
plt.xlabel('Sales Amount')
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.show()
图表解读: 箱线图会清晰地显示出那个位于上方的离群点(5000),以及数据的四分位距和中位数。
洞察 2: 我们想了解销售额的分布形态(是正态分布还是偏态?)。
- 决策: 直方图 或 核密度估计图 可以很好地展示分布形态。
# 绘制销售额的直方图和核密度估计图
plt.figure(figsize=(10, 6))
sns.histplot(df['sales'].dropna(), kde=True, bins=30) # .dropna() 忽略缺失值'Sales Distribution (Histogram with KDE)')
plt.xlabel('Sales Amount')
plt.ylabel('Frequency')
plt.show()
图表解读: 图表会显示销售额的分布频率,KDE曲线平滑了直方图,让我们更容易看出整体分布趋势,从 describe 我们知道中位数和均值接近,所以这里我们期望看到一个大致对称的钟形曲线。
洞察 3: 我们想比较不同地区的平均销售额。
- 决策: 条形图 是比较不同类别均值的经典选择。
# 计算各地区的平均销售额
avg_sales_by_region = df.groupby('region')['sales'].mean().sort_values(ascending=False)
# 绘制条形图
plt.figure(figsize=(10, 6))
sns.barplot(x=avg_sales_by_region.index, y=avg_sales_by_region.values, palette='viridis')'Average Sales by Region')
plt.xlabel('Region')
plt.ylabel('Average Sales Amount')
plt.show()
图表解读: 条形图的高度直观地展示了哪个地区的平均销售额最高,哪个最低。
洞察 4: 我们想探究年龄和销售额之间是否存在关系。
- 决策: 散点图 是查看两个连续变量之间关系的标准工具。
# 绘制年龄和销售额的散点图
plt.figure(figsize=(10, 8))
sns.scatterplot(x='age', y='sales', data=df, alpha=0.6) # alpha设置透明度,便于观察重叠点'Sales vs. Age')
plt.xlabel('Age')
plt.ylabel('Sales Amount')
plt.grid(True, linestyle='--', alpha=0.7)
plt.show()
图表解读: 散点图可以帮助我们判断年龄和销售额是正相关、负相关还是不相关。
describe 与作图的对应关系
describe 提供的信息 |
推荐的图表 | 图表目的 |
|---|---|---|
| 数据分布形态 (均值、中位数、标准差、分位数) | 直方图、核密度估计图 | 查看数据是正态、偏态还是双峰分布。 |
| 数据分布与异常值 (最小值、最大值、四分位数) | 箱线图 | 直观展示数据的中位数、四分位距和离群点。 |
| 不同类别的比较 (均值、中位数、计数) | 条形图、小提琴图、箱线图 | 比较不同组别之间的集中趋势或分布差异。 |
| 两个连续变量的关系 | 散点图 | 探索变量之间是否存在线性或非线性关系。 |
| 缺失值数量 | 缺失值矩阵图 (sns.heatmap(df.isnull())) |
直观地查看数据集中缺失值的位置和模式。 |
最终结论:
describe 是数据可视化流程中不可或缺的第一步,它通过提供数据的量化摘要,为你指明了数据的关键特征和潜在问题,从而让你能够胸有成竹地选择最合适的图表来讲述数据背后的故事,先理解数据,再展示数据。