SQLAlchemy 教程:从入门到精通
SQLAlchemy 是 Python 中最强大、最流行的 SQL 工具包和对象关系映射器,它为开发者提供了两个主要的使用模式:

- ORM (Object Relational Mapping):以面向对象的方式操作数据库,你定义 Python 类,SQLAlchemy 会自动将其映射到数据库表,你通过操作对象来间接操作数据库,这是最常用、最方便的模式。
- Core (Core):提供一套 Pythonic 的、基于 Python 表达式的语言来构建 SQL 语句,它更接近原生 SQL,提供了更大的灵活性和性能控制。
本教程将主要围绕更常用的 ORM 模式展开,并在最后简要介绍 Core 模式。
目录
-
第一部分:核心概念与安装
- 什么是 SQLAlchemy?
- 安装 SQLAlchemy
- SQLAlchemy 的核心组件:Engine, Connection, Session
-
第二部分:ORM 基础操作
- 定义模型
- 创建数据库表
- 增删改查
- 创建与添加
- 查询
- 更新与删除
-
第三部分:进阶查询
 (图片来源网络,侵删)
(图片来源网络,侵删)filter()vs.filter_by()- 排序与分页
- 关系
- 一对多
- 多对一
- 多对多
-
第四部分:Core 模式简介
Table,Column,MetaData- 构建
select语句
-
第五部分:最佳实践与总结
- 代码结构建议
- 资源管理
第一部分:核心概念与安装
什么是 SQLAlchemy?
SQLAlchemy 是一座桥梁,连接了 Python 对象世界和 SQL 数据库世界,它让你不必手写复杂的 SQL 语句,而是用 Python 的类和方法来完成数据库操作,这极大地提高了开发效率和代码的可维护性。
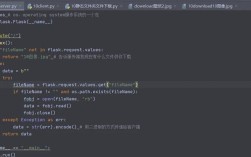
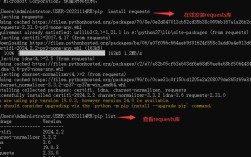
安装 SQLAlchemy
使用 pip 进行安装:

pip install SQLAlchemy
SQLAlchemy 的核心组件
在深入代码之前,必须理解三个核心组件:
-
Engine (引擎):这是 SQLAlchemy 与数据库交互的核心,它管理着与数据库的连接池,负责处理连接的创建和销毁,你只需要创建一次 Engine 对象。
-
Connection (连接):由 Engine 提供,代表一个与数据库的实时连接,通常你不需要直接操作它,而是通过更高层级的 Session。
-
Session (会话):这是 ORM 交互的主要“接口”,它维护一个对象映射到数据库记录的“身份映射”,并跟踪所有待执行的增删改操作,你可以把它想象成一个“工作区”,你在这个工作区里操作对象,然后通过
commit()将这些操作一次性提交到数据库。
一个简单的比喻:
- Engine 是一家工厂。
- Session 是工厂里的一个车间。
- 对象 是车间里的工人。
commit()就是把车间里完成的工作成品运出去。
第二部分:ORM 基础操作
定义模型
模型是一个 Python 类,它继承自 sqlalchemy.ext.declarative.declarative_base,这个类中的属性会自动映射为数据库表的列。
import os
from sqlalchemy import create_engine, Column, Integer, String
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_base
# 1. 创建一个基础类
Base = declarative_base()
# 2. 定义一个模型类 (User)
class User(Base):
__tablename__ = 'users' # 指定数据库表名
id = Column(Integer, primary_key=True)
name = Column(String)
fullname = Column(String)
age = Column(Integer)
def __repr__(self):
return f"<User(name='{self.name}', fullname='{self.fullname}', age={self.age})>"
# 3. 创建数据库连接 (Engine)
# 这里使用 SQLite 作为示例,它是一个文件型数据库,无需额外安装服务器
# 'sqlite:///tutorial.db' 表示在当前目录下创建一个名为 tutorial.db 的数据库文件
engine = create_engine('sqlite:///tutorial.db')
# 4. 创建表 (如果表不存在)
Base.metadata.create_all(engine)
print("数据库表 'users' 已创建。")
运行这段代码后,你的项目目录下会生成一个 tutorial.db 文件,这就是你的数据库。
创建数据库表
上面的代码中,Base.metadata.create_all(engine) 会检查所有继承自 Base 的模型,并根据模型的定义在数据库中创建对应的表,如果表已经存在,它不会重复创建。
增删改查
创建与添加
我们需要一个 Session 来操作数据库。
# ... (接上面的代码)
# 5. 创建一个 Session
Session = sessionmaker(bind=engine)
session = Session()
# 6. 创建新用户对象
user1 = User(name='Alice', fullname='Alice Smith', age=30)
user2 = User(name='Bob', fullname='Bob Johnson', age=25)
# 7. 将对象添加到会话
# 这些对象处于 "pending" 状态,还没有真正写入数据库
session.add(user1)
session.add(user2)
# 8. 提交会话
# 这会将所有 "pending" 状态的对象操作发送到数据库,执行 INSERT 语句
session.commit()
print("用户已添加到数据库。")
查询
查询是 ORM 最强大的功能之一。
# ... (接上面的代码)
# 查询所有用户
all_users = session.query(User).all()
print("\n--- 所有用户 ---")
for user in all_users:
print(user)
# 查询特定条件的用户
# 使用 filter() 进行条件过滤
print("\n--- 名为 Alice 的用户 ---")
alice = session.query(User).filter_by(name='Alice').first() # .first() 只取第一个结果
print(alice)
# 使用 filter() (更强大,支持复杂的表达式)
print("\n--- 年龄大于 28 的用户 ---")
older_users = session.query(User).filter(User.age > 28).all()
for user in older_users:
print(user)
# 获取单个列
print("\n--- 只获取用户名 ---")
names = session.query(User.name).all()
print(names) # 输出: [('Alice',), ('Bob',)]
更新与删除
更新和删除操作通常遵循一个模式:先查询,再修改,最后提交。
# ... (接上面的代码)
# 更新
# 1. 查询要更新的对象
bob_to_update = session.query(User).filter_by(name='Bob').first()
# 2. 修改对象的属性
if bob_to_update:
bob_to_update.age = 26
print(f"\n--- 更新 Bob 的年龄为 {bob_to_update.age} ---")
# 3. 提交更改
session.commit()
# 删除
# 1. 查询要删除的对象
alice_to_delete = session.query(User).filter_by(name='Alice').first()
# 2. 从会话中删除
if alice_to_delete:
session.delete(alice_to_delete)
print(f"\n--- 删除 Alice ---")
# 3. 提交更改
session.commit()
# 验证删除
print("\n--- 删除后的所有用户 ---")
remaining_users = session.query(User).all()
for user in remaining_users:
print(user)
第三部分:进阶查询
filter() vs. filter_by()
-
filter_by():- 使用关键字参数,如
filter_by(name='Alice')。 - 只支持简单的 比较。
- 更简洁,但功能有限。
- 使用关键字参数,如
-
filter():- 使用标准的 Python 运算符,如
filter(User.name == 'Alice')。 - 支持复杂的表达式,如
User.age > 25,User.name.like('A%'),~User.name.in_(['Bob', 'Charlie'])。 - 功能更强大,是推荐使用的查询方式。
- 使用标准的 Python 运算符,如
排序与分页
from sqlalchemy import desc
# 假设我们有更多用户
session.add_all([
User(name='Charlie', fullname='Charlie Brown', age=35),
User(name='David', fullname='David Copperfield', age=28)
])
session.commit()
# 排序
print("\n--- 按年龄升序排列 ---")
users_by_age_asc = session.query(User).order_by(User.age).all()
for user in users_by_age_asc:
print(user)
print("\n--- 按年龄降序排列 ---")
users_by_age_desc = session.query(User).order_by(desc(User.age)).all