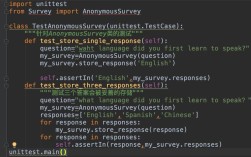
Python 标准库中并没有一个名为 multitasking 的官方模块。

这个名称通常是一个统称,或者是一些第三方库(如 multitasking)的名字,用来描述 Python 中实现“同时执行多个任务”这一目标的多种技术,当我们谈论 Python 的多任务时,我们通常指的是以下三种主要方式,它们分别由不同的标准库模块支持:
- 多进程
- 多线程
- 异步 I/O (Async I/O)
下面我将详细解释这三种方式,并介绍它们各自的核心模块、适用场景和优缺点。
多进程
多进程是利用计算机的多个 CPU 核心来真正并行地执行任务,每个进程都有自己独立的内存空间,就像一个独立的程序。
- 核心模块:
multiprocessing - 工作原理: 创建多个进程,每个进程运行 Python 解释器的一个副本,操作系统负责将它们分配到不同的 CPU 核心上执行,由于进程间内存独立,数据共享需要通过特殊的机制(如
Queue,Pipe,Manager)来实现,这避免了多线程中常见的“竞态条件”问题。 - 适用场景:
- CPU 密集型任务: 如科学计算、图像处理、视频编码等,这些任务需要大量的计算资源。
- 需要利用多核 CPU 来显著提升程序运行速度。
- 任务之间需要高度隔离,避免相互影响。
示例代码 (multiprocessing)
import multiprocessing
import time
def worker(num):
"""一个简单的 worker 函数"""
print(f'Worker {num} 开始')
time.sleep(2) # 模拟耗时操作
print(f'Worker {num} 结束')
return f'Worker {num} 的结果'
if __name__ == '__main__':
# 创建一个进程池
with multiprocessing.Pool(processes=4) as pool:
# 创建任务列表
numbers = [1, 2, 3, 4]
# 使用 pool.map 同步方式执行,会等待所有任务完成
# results = pool.map(worker, numbers)
# 使用 pool.map_async 异步方式执行,可以立即得到一个结果对象
result_obj = pool.map_async(worker, numbers)
print("主线程继续执行,不必等待 worker 完成...")
# 从结果对象中获取结果,如果任务还没完成,会在这里等待
results = result_obj.get()
print("\n所有任务结果:")
for res in results:
print(res)
多线程
多线程是在单个进程内创建多个线程,这些线程共享同一块内存空间,由于 Python 的全局解释器锁,在任意时刻只有一个线程能执行 Python 字节码,这意味着 Python 的多线程并不能实现真正的并行计算,但它对于I/O 密集型任务非常有效。

- 核心模块:
threading - 工作原理: 线程在进程内部运行,共享进程的资源(如内存、文件句柄),当一个线程遇到 I/O 操作(如网络请求、文件读写)而阻塞时,GIL 会被释放,允许其他线程运行,从而提高了程序的响应速度。
- 适用场景:
- I/O 密集型任务: 如网络爬虫、Web 服务器、数据库查询等。
- 需要同时处理多个用户的请求或多个网络连接。
- 任务之间需要频繁共享数据。
示例代码 (threading)
import threading
import time
def worker(num):
"""一个简单的 worker 函数"""
print(f'线程 {num} 开始')
time.sleep(2) # 模拟 I/O 阻塞
print(f'线程 {num} 结束')
if __name__ == '__main__':
threads = []
# 创建并启动 4 个线程
for i in range(4):
t = threading.Thread(target=worker, args=(i,))
threads.append(t)
t.start()
print("主线程继续执行,不必等待其他线程完成...")
# 等待所有线程执行完毕
for t in threads:
t.join()
print("所有线程已结束。")
异步 I/O (Async I/O)
异步编程是一种单线程内的并发模型,它通过“协程”来管理任务,当一个任务遇到 I/O 操作时,它会主动“让出”控制权,让运行器去执行其他已准备好的任务,当 I/O 操作完成时,这个任务会被重新唤醒。
- 核心模块:
asyncio(Python 3.4+ 内置) - 工作原理: 使用
async和await关键字定义协程,事件循环是asyncio的核心,它负责调度和执行所有协程,这种方式避免了线程切换的开销,并且没有 GIL 的限制,是处理高并发 I/O 操作的利器。 - 适用场景:
- 极高并发的 I/O 密集型任务: 如 Web 服务器(如 FastAPI, Quart)、实时聊天应用、网络爬虫(爬取大量网站)。
- 需要处理成千上万个并发连接,而线程数过多会导致资源耗尽。
示例代码 (asyncio)
import asyncio
import time
async def worker(num):
"""一个异步的 worker 函数"""
print(f'协程 {num} 开始')
# await asyncio.sleep() 是一个非阻塞的 I/O 操作,会让出控制权
await asyncio.sleep(2)
print(f'协程 {num} 结束')
return f'协程 {num} 的结果'
async def main():
# 创建任务列表
tasks = [worker(i) for i in range(4)]
# asyncio.gather 会并发执行所有任务,并收集结果
results = await asyncio.gather(*tasks)
print("\n所有任务结果:")
for res in results:
print(res)
# Python 3.7+ 可以直接运行 asyncio.run()
asyncio.run(main())
总结与对比
| 特性 | 多进程 (multiprocessing) |
多线程 (threading) |
异步 I/O (asyncio) |
|---|---|---|---|
| 核心概念 | 进程 | 线程 | 协程 |
| 并行性 | 真正的并行 (多核) | 并发 (单核),非并行 | 并发 (单线程),非并行 |
| GIL | 不受 GIL 限制 | 受 GIL 限制 | 不受 GIL 限制 |
| 内存占用 | 高 (每个进程独立内存) | 低 (共享进程内存) | 最低 (单线程) |
| 数据共享 | 复杂 (需 Queue, Pipe) | 简单 (共享内存) | 需用特殊结构 (如 asyncio.Queue) |
| 适用场景 | CPU 密集型 | I/O 密集型 (并发度不高) | 极高并发 的 I/O 密集型 |
| 创建/切换开销 | 高 (进程创建和销毁成本高) | 中 (线程切换有开销) | 低 (协程切换在用户态,成本极低) |
| 代码复杂度 | 中等 | 中等 (需处理锁) | 较高 (需理解事件循环和 async/await) |
如何选择?
-
如果你的任务是 CPU 密集型:进行大量的数学运算、数据处理。选择多进程 (
multiprocessing),因为它能真正利用多核 CPU。 -
如果你的任务是 I/O 密集型,且并发量不是特别高:一个爬虫需要同时爬取几十个网站。选择多线程 (
threading),它简单易用,能有效利用 I/O 等待时间。 -
如果你的任务是 I/O 密集型,且需要处理成千上万的并发连接:构建一个高性能的 Web API 或 WebSocket 服务器。选择异步 I/O (
asyncio),它在高并发场景下性能远超多线程,且资源消耗更低。
multitasking 第三方库
确实存在一个名为 multitasking 的第三方 PyPI 库,它通常是一个“语法糖”库,旨在简化异步编程,比如提供 @multitasking.task 这样的装饰器来快速创建后台任务,但其底层实现仍然是基于 asyncio 的,对于初学者,直接学习 asyncio 和 async/await 是更推荐的做法,因为它能让你更深入地理解异步编程的原理。
希望这个详细的解释能帮助你理解 Python 中的多任务处理!