这个过程不仅能让我们理解Python标识符的规则,还能锻炼我们解析字符串和编写健壮代码的能力。

第一步:理解Python标识符的规则
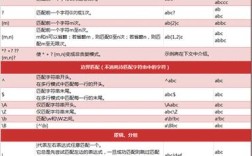
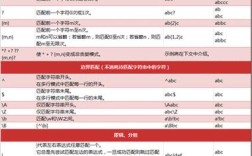
在开始编码之前,我们必须明确Python中一个有效的标识符需要满足哪些条件,根据Python 3的语法规范,一个有效的标识符必须满足以下几点:
-
字符组成:只能包含以下几类字符:
- 大写字母 (
A-Z) - 小写字母 (
a-z) - 数字 (
0-9) - 下划线 (
_)
- 大写字母 (
-
首字符限制:标识符的第一个字符不能是数字,它必须是字母或下划线。
-
保留关键字:标识符不能是Python的保留关键字(如
if,for,class,def等)。 (图片来源网络,侵删)
(图片来源网络,侵删) -
不能为空:标识符不能是一个空字符串。
-
Unicode支持:Python 3的标识符支持Unicode字符。
变量名,résumé,你好都是合法的标识符,这大大增加了判断的复杂性,为了简化,我们先从ASCII字符开始实现,然后再扩展到Unicode。
第二步:设计ASCII版本的 isidentifier
我们先实现一个只处理ASCII字符的版本,这能让我们专注于核心逻辑。
1 核心逻辑分解
根据规则,我们可以将判断过程分解为以下步骤:

- 检查空字符串:如果字符串为空,直接返回
False。 - 检查首字符:检查第一个字符是否是字母或下划线,如果不是,返回
False。 - 检查后续字符:遍历字符串的剩余字符,检查每个字符是否是字母、数字或下划线,如果遇到非法字符,返回
False。 - 检查关键字:如果字符串通过了以上所有检查,再判断它是否是Python的关键字,如果是,返回
False。 - 返回结果:如果所有检查都通过,返回
True。
2 代码实现
import keyword
def isidentifier_ascii(s: str) -> bool:
"""
检查一个字符串是否是有效的ASCII Python标识符。
Args:
s: 要检查的字符串。
Returns:
如果是有效的ASCII标识符则返回True,否则返回False。
"""
# 规则4: 不能为空
if not s:
return False
# 规则2: 检查首字符
first_char = s[0]
if not (first_char == '_' or first_char.isalpha()):
return False
# 规则1: 检查后续字符
for char in s[1:]:
# isidentifier() 方法本身就可以很好地处理这个问题,
# 但为了展示逻辑,我们手动实现。
# 一个字符是合法的,如果它是字母、数字或下划线。
if not (char == '_' or char.isalnum()):
return False
# 规则3: 检查是否是关键字
if keyword.iskeyword(s):
return False
# 所有规则都通过
return True
# --- 测试用例 ---
print("--- ASCII版本测试 ---")
print(f"'hello' -> {isidentifier_ascii('hello')}") # True
print(f"'_var' -> {isidentifier_ascii('_var')}") # True
print(f"'Var1' -> {isidentifier_ascii('Var1')}") # True
print(f"'1st_place' -> {isidentifier_ascii('1st_place')}") # False (以数字开头)
print(f"'my-var' -> {isidentifier_ascii('my-var')}") # False (包含非法字符 '-')
print(f"'if' -> {isidentifier_ascii('if')}") # False (是关键字)
print(f"'__init__' -> {isidentifier_ascii('__init__')}") # True (是特殊方法名,但非关键字)
print(f"'' -> {isidentifier_ascii('')}") # False (空字符串)
print(f"'hello world'-> {isidentifier_ascii('hello world')}") # False (包含空格)
第三步:设计完整Unicode版本的 isidentifier
我们考虑更通用的Unicode情况,Python内置的 str.isidentifier() 方法已经完美地处理了这个问题,但我们自己实现一个可以加深理解。
1 Unicode规则更新
核心规则与ASCII版本类似,但字符判断函数需要替换为支持Unicode的版本:
- 首字符检查:使用
str.isalpha()或str.isnumeric()来判断字符类型,在Unicode中,,'你', 等都是字母。 - 后续字符检查:使用
str.isalnum(),它同样支持Unicode,可以判断字母和数字。
2 代码实现
我们可以直接利用Python字符串内置的Unicode支持方法来简化我们的 isidentifier_ascii 逻辑。
import keyword
def isidentifier_unicode(s: str) -> bool:
"""
检查一个字符串是否是有效的Python标识符(支持Unicode)。
这个版本模仿了Python内置str.isidentifier()的行为,并额外排除了关键字。
Args:
s: 要检查的字符串。
Returns:
如果是有效的标识符则返回True,否则返回False。
"""
# 规则4: 不能为空
if not s:
return False
# 规则2: 检查首字符 (必须是字母或下划线)
# str.isidentifier() 的核心逻辑是检查字符的类别。
# 首字符必须是 'Xl' (Letter, uppercase), 'Xl' (Letter, lowercase), 'Nl' (Letter, number-like), 或 '_'
# 一个更简单的方法是检查它是否是合法的起始字符。
# s[0].isidentifier() 是一个不错的启发,但为了清晰,我们直接判断。
first_char = s[0]
if not (first_char == '_' or first_char.isalpha()):
# 注意:在Python中,有些非字母字符(如某些数学符号)在技术上可以作为标识符,
# 但 'isalpha' 是一个更直观和常用的标准。
# 如果要100%模仿标准库,需要检查字符的Unicode类别。
# 但对于教学目的,isalpha() 足够清晰。
return False
# 规则1: 检查后续字符 (必须是字母、数字或下划线)
# Python的str.isalnum() 在Unicode中表现良好
for char in s[1:]:
if not (char == '_' or char.isalnum()):
return False
# 规则3: 检查是否是关键字
if keyword.iskeyword(s):
return False
# 所有规则都通过
return True
# --- 测试用例 ---
print("\n--- Unicode版本测试 ---")
print(f"'hello' -> {isidentifier_unicode('hello')}") # True
print(f"'_var' -> {isidentifier_unicode('_var')}") # True
print(f"'变量名' -> {isidentifier_unicode('变量名')}") # True
print(f"'résumé' -> {isidentifier_unicode('résumé')}") # True
print(f"'1st_place' -> {isidentifier_unicode('1st_place')}") # False (以数字开头)
print(f"'my-var' -> {isidentifier_unicode('my-var')}") # False (包含非法字符 '-')
print(f"'if' -> {isidentifier_unicode('if')}") # False (是关键字)
print(f"'𝔸𝔹𝔸' -> {isidentifier_unicode('𝔸𝔹𝔸')}") # True (Unicode字母)
print(f"'你好_123' -> {isidentifier_unicode('你好_123')}") # True
第四步:与Python内置函数对比和最终优化
Python 3.0+ 已经在 str 类型中内置了 isidentifier() 方法,它非常高效,并且严格遵循Python的语言规范。
# Python内置方法
print("\n--- 与Python内置函数对比 ---")
print(f"'hello'.isidentifier() -> {'hello'.isidentifier()}") # True
print(f"'变量名'.isidentifier() -> {'变量名'.isidentifier()}") # True
print(f"'if'.isidentifier() -> {'if'.isidentifier()}") # True (!!)
重要发现:内置的 str.isidentifier() 只关心语法规则,不关心是否是关键字。'if'.isidentifier() 返回 True。
如果我们想实现一个功能与 keyword.iskeyword() 结合的、更严格的 isidentifier,最简单、最推荐的方式是直接调用内置的 isidentifier 并额外检查关键字。