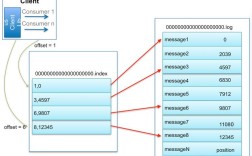
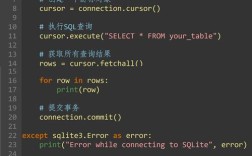
当然可以!Python 提供了非常强大的工具来处理和操作 HTML,其中最主要和最推荐的方法是使用 正则表达式 和 专门的 HTML 解析库。

(图片来源网络,侵删)
我会从简单到复杂,为你详细介绍几种方法。
核心概念
- 正则表达式: 一种用来匹配字符串模式的强大工具,它非常适合处理有固定、规则可循的文本。
- HTML 解析库: 专门为解析 HTML/XML 文档设计的库,它们能将 HTML 文档转换成一个结构化的对象(如树),让你可以方便地通过标签、属性、CSS 选择器等来查找和修改内容,而无需关心复杂的正则表达式。
使用正则表达式 (不推荐,但需了解)
正则表达式看起来很直接,但强烈不推荐用它来解析复杂的、不规范的 HTML,HTML 的结构非常灵活(标签可以嵌套、属性顺序可以打乱、标签可以没有闭合等),用正则表达式来匹配很容易出错。
何时可以考虑使用?
- 当你处理的 HTML 片段非常简单且固定,你只是想从中提取一个明确的、格式不变的文本时。
- 当你只是进行一些非常简单的“查找和替换”操作时。
示例:提取所有 <a> 标签的 href 属性
假设我们有以下 HTML 字符串:
html_string = """
<html>
<body>
<h1>我的网站</h1>
<p>欢迎访问!</p>
<a href="https://www.google.com">Google</a>
<a href="/about.html">关于我们</a>
<div>这是一个没有链接的div。</div>
</body>
</html>
"""
我们可以用 re 模块来提取 href。

(图片来源网络,侵删)
import re # 正则表达式解释: # <a\s+ : 匹配 <a 标签开头,后面跟至少一个空白字符 # (?:[^>]*?\s+)? : 非捕获组,匹配任意非 > 的字符(非贪婪),至少一个空白字符(可选,为了处理 href="..." 这样的格式) # href\s*=\s* : 匹配 href 属性,等号两边可以有空白 # (["']) : 捕获引号(单引号或双引号),并放入 group(1) # (.*?) : 捕获引号内的内容(非贪婪),放入 group(2) # \1 : 匹配前面捕获到的第一个引号(确保是闭合的) # [^>]*> : 匹配 a 标签的剩余部分直到 > pattern = r'<a\s+(?:[^>]*?\s+)?href\s*=\s*(["\'])(.*?)\1[^>]*>' # re.findall 会返回所有匹配到的 group(2) 的内容 hrefs = re.findall(pattern, html_string) # findall 返回的是元组列表,我们需要提取第二个元素 href_list = [href[1] for href in hrefs] print(href_list) # 输出: ['https://www.google.com', '/about.html']
为什么正则表达式不好?
- HTML 换行,
\s可能会匹配到换行符,导致失败。 - 如果属性顺序是
class="link" href="...",上面的正则表达式可能会失效。 - 如果标签是
<a HREF='...'>(大写),也需要处理。 - 无法处理嵌套的复杂结构。
使用专门的 HTML 解析库 (强烈推荐)
这是处理 Python 和 HTML 的正确方式,它们能更好地处理 HTML 的不规范性和复杂性。
BeautifulSoup (最常用、最易上手)
BeautifulSoup 是一个强大的库,它可以将复杂的 HTML 转换成一个复杂的树形结构,你只需要调用简单的方法和属性就能找到你想要的内容,它通常配合另一个库 lxml 一起使用,因为 lxml 的解析速度非常快。
安装
pip install beautifulsoup4 pip install lxml # 推荐安装,解析速度最快
示例:用 BeautifulSoup 提取所有 <a> 标签的 href 属性
from bs4 import BeautifulSoup
html_string = """
<html>
<body>
<h1>我的网站</h1>
<p>欢迎访问!</p>
<a href="https://www.google.com" class="main-link">Google</a>
<a href="/about.html" id="about-link">关于我们</a>
<div>这是一个没有链接的div。</div>
</body>
</html>
"""
# 创建一个 BeautifulSoup 对象
# 'lxml' 是我们使用的解析器
soup = BeautifulSoup(html_string, 'lxml')
# 1. 查找所有的 <a> 标签
# find_all() 返回一个列表,包含所有匹配的标签对象
all_a_tags = soup.find_all('a')
print("--- 查找所有 <a> 标签 ---")
for tag in all_a_tags:
print(tag)
# 2. 提取 href 属性
# 标签对象的属性可以通过字典的方式访问
hrefs = [tag['href'] for tag in all_a_tags]
print("\n--- 提取到的所有 href ---")
print(hrefs) # 输出: ['https://www.google.com', '/about.html']
# 3. 查找特定属性的标签
# 查找 class 为 "main-link" 的 a 标签
specific_link = soup.find('a', class_='main-link')
print("\n--- 查找特定 class 的链接 ---")
if specific_link:
print(f"找到链接: {specific_link.text}, URL: {specific_link['href']}")
# 4. 使用 CSS 选择器 (更强大、更直观)
# BeautifulSoup 支持 CSS 选择器,语法和前端开发一样
# select() 返回一个列表,select_one() 返回第一个匹配的元素
first_link = soup.select_one('a.main-link')
all_links_by_selector = soup.select('a')
print("\n--- 使用 CSS 选择器 ---")
print(f"通过选择器找到的第一个链接: {first_link['href']}")
print(f"通过选择器找到的所有链接数量: {len(all_links_by_selector)}")
lxml (高性能,功能强大)
lxml 也是一个非常优秀的库,速度极快,功能比 BeautifulSoup 更底层,也更强大,它支持 XPath 和 CSS 选择器。
安装
pip install lxml
示例:用 lxml 提取 <a> 标签的 href
from lxml import html
html_string = """
<html>
<body>
<h1>我的网站</h1>
<p>欢迎访问!</p>
<a href="https://www.google.com" class="main-link">Google</a>
<a href="/about.html" id="about-link">关于我们</a>
<div>这是一个没有链接的div。</div>
</body>
</html>
"""
# 解析 HTML
tree = html.fromstring(html_string)
# 使用 XPath 查询
# //a 表示查找所有层级的 <a> 标签
# @href 表示获取 href 属性
hrefs = tree.xpath('//a/@href')
print("--- 使用 XPath 提取 href ---")
print(hrefs) # 输出: ['https://www.google.com', '/about.html']
# 使用 CSS 选择器查询
# 需要先安装 cssselect 模块
# pip install cssselect
links = tree.cssselect('a')
hrefs_css = [link.get('href') for link in links]
print("\n--- 使用 CSS 选择器提取 href ---")
print(hrefs_css)
总结与选择
| 特性 | 正则表达式 (re) |
BeautifulSoup | lxml |
|---|---|---|---|
| 易用性 | 低,规则复杂难写 | 非常高,API 直观 | 中等,需要了解 XPath/CSS |
| 健壮性 | 差,易被不规范 HTML 搞垮 | 高,容错能力强 | 高,容错能力强 |
| 性能 | 快(对于简单匹配) | 中等(依赖底层解析器) | 非常快 |
| 适用场景 | 简单、固定的文本匹配;非 HTML 场景 | 绝大多数场景,爬虫,数据提取 | 大规模数据抓取,需要高性能的场景 |
| 学习曲线 | 陡峭 | 平缓 | 中等 |
最终建议:
- 对于 99% 的 Python HTML 处理任务,请直接使用
BeautifulSoup。 它简单、强大、可靠,是解决这个问题的标准工具。 - 只有在追求极致性能,或者你对 XPath 非常熟悉时,才考虑直接使用
lxml。 - 尽量避免使用正则表达式来解析完整的 HTML 文档。 除非你非常清楚你在做什么,并且处理的 HTML 格式极其简单。