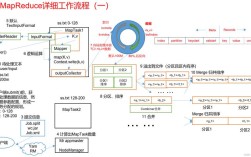
Of course! The term "process line" in Python almost always refers to reading a file, handling each line of that file one by one, and doing something with it (e.g., parsing, transforming, or analyzing the content).

This is a fundamental task in programming, especially in data processing, log analysis, and text manipulation.
Let's break down the best ways to do this, from the classic to the most modern and recommended.
The Core Concept: Iteration
The key idea is that files in Python are iterable. This means you can loop over them, and in each iteration of the loop, you get one line from the file as a string.
Method 1: The Classic for Loop (Most Common & Recommended)
This is the most Pythonic, readable, and memory-efficient way to process a file line by line. It's the standard you should use in most cases.

How it works: The with open(...) statement ensures the file is automatically closed, even if errors occur. The for line in file: loop reads one line into memory at a time.
Example: Counting Lines and Printing Them
# Use a descriptive variable name for the file path
file_path = 'my_document.txt'
# The 'with' statement is the best practice for handling files
with open(file_path, 'r') as file:
line_count = 0
for line in file:
# The 'line' variable includes the newline character '\n' at the end
# We can strip it if we don't want it
clean_line = line.strip()
# Do something with the line
line_count += 1
print(f"Line {line_count}: {clean_line}")
print(f"\nTotal lines processed: {line_count}")
Key Points:
with open(...): This is the modern, safe way to open files. It handles closing the file for you.'r': This is the mode for reading. It's the default, so you could omit it, but it's good to be explicit.for line in file: This is the magic. It's highly efficient because it doesn't load the entire file into memory. It streams the file line by line.line.strip(): This is a very common operation. It removes leading and trailing whitespace, including the invisible\nnewline character. If you need to keep the newline, you can skip this.
Method 2: The readlines() Method (Use with Caution)
This method reads the entire file into a list of strings, where each string is a line from the file.
When to use it: Only when you need random access to lines (e.g., lines[10]) or if you are certain the file is small enough to fit into your computer's memory.

When NOT to use it: Never for large files (e.g., multi-gigabyte log files), as it will consume all available memory and likely crash your program.
Example: Processing a Small File with readlines()
file_path = 'my_document.txt'
with open(file_path, 'r') as file:
# readlines() loads the WHOLE file into a list
all_lines = file.readlines()
print(f"Total lines in the list: {len(all_lines)}")
# Now you can process the list
for i, line in enumerate(all_lines):
# The line still has the '\n' at the end
clean_line = line.strip()
print(f"Line {i+1}: {clean_line}")
Method 3: The readline() Method (For Fine-Grained Control)
This method reads exactly one line from the file. You call it repeatedly in a loop until it returns an empty string, which signals the end of the file.
This method is less common than the classic for loop but is useful if you need more control over the reading process or if you are building a more complex parser.
Example: Using readline() in a while loop
file_path = 'my_document.txt'
with open(file_path, 'r') as file:
line_count = 0
while True:
# Read a single line
line = file.readline()
# If readline() returns an empty string, we've reached the end
if not line:
break
line_count += 1
clean_line = line.strip()
print(f"Line {line_count}: {clean_line}")
print(f"\nTotal lines processed: {line_count}")
Practical Scenarios & Common Tasks
Here are some common things you'll do while processing lines.
Scenario 1: Filtering Lines
Let's say you only want to process lines that contain the word "error".
file_path = 'server.log'
with open(file_path, 'r') as file:
for line in file:
if 'ERROR' in line:
# We found an error line, let's process it
clean_line = line.strip()
print(f"Found error: {clean_line}")
Scenario 2: Parsing CSV Lines
If your file is a CSV, using the csv module is much safer than splitting by commas, as it correctly handles quoted fields that contain commas.
import csv
file_path = 'data.csv'
with open(file_path, 'r', newline='') as csvfile:
# csv.reader creates an object that iterates over lines in the CSV file
csv_reader = csv.reader(csvfile)
# The header is the first line
header = next(csv_reader)
print(f"Header: {header}")
# Process the rest of the rows
for row in csv_reader:
# row is a list of strings for each column
# e.g., ['John Doe', '30', 'New York']
name = row[0]
age = row[1]
print(f"Processing user: {name}, Age: {age}")
Scenario 3: Writing Processed Lines to a New File
A very common pattern is to read from one file, modify each line, and write to another.
input_file_path = 'my_document.txt'
output_file_path = 'processed_document.txt'
with open(input_file_path, 'r') as infile, open(output_file_path, 'w') as outfile:
for line in infile:
# Example: Convert line to uppercase
processed_line = line.upper()
# Write the processed line to the new file
# The 'w' mode will overwrite the file if it exists.
# Use 'a' (append) to add to the end of an existing file.
outfile.write(processed_line)
print(f"Processing complete. Output saved to {output_file_path}")
Summary: Which Method to Choose?
| Method | When to Use | Memory Usage | Readability |
|---|---|---|---|
for line in file |
Almost always. The default, best choice. | Very Low (Streaming) | Excellent |
file.readlines() |
Only for small files or when you need random access. | High (Loads entire file) | Good |
file.readline() |
When you need fine-grained, manual control over reading. | Low (Line by line) | Fair (more verbose) |
For 99% of your line-processing needs, stick with the for line in file: pattern inside a with open(...) block. It's the most efficient, safest, and clearest way to do it.