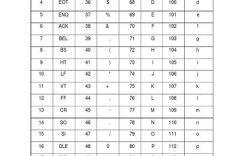
方法 1:使用 char 和强制类型转换
将字符串的每个字符转换为对应的 ASCII/Unicode 码点(int 类型)。

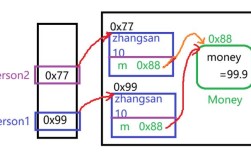
(图片来源网络,侵删)
public class StringToAscii {
public static void main(String[] args) {
String str = "Hello";
for (int i = 0; i < str.length(); i++) {
char ch = str.charAt(i);
int ascii = (int) ch; // 强制转换为 int
System.out.println("字符: " + ch + " -> ASCII/Unicode: " + ascii);
}
}
}
输出:
字符: H -> ASCII/Unicode: 72
字符: e -> ASCII/Unicode: 101
字符: l -> ASCII/Unicode: 108
字符: l -> ASCII/Unicode: 108
字符: o -> ASCII/Unicode: 111方法 2:使用 `String.getBytes()
将字符串转换为字节数组(默认使用平台编码,如 UTF-8),然后转换为 ASCII 码。
public class StringToAscii {
public static void main(String[] args) {
String str = "Hello";
byte[] bytes = str.getBytes(); // 默认使用 UTF-8 编码
for (byte b : bytes) {
int ascii = b & 0xFF; // 避免负数(Java 的 byte 是有符号的)
System.out.println("字节: " + b + " -> ASCII: " + ascii);
}
}
}
输出:
字节: 72 -> ASCII: 72
字节: 101 -> ASCII: 101
字节: 108 -> ASCII: 108
字节: 108 -> ASCII: 108
字节: 111 -> ASCII: 111注意:

(图片来源网络,侵删)
- 如果字符串包含非 ASCII 字符(如中文),
getBytes()可能会返回多个字节(UTF-8 编码)。 - 如果需要严格 ASCII(0-127),可以检查
ascii <= 127。
方法 3:使用 String.codePointAt()
处理 Unicode 码点(适用于代理对,如某些 Emoji 或特殊字符)。
public class StringToAscii {
public static void main(String[] args) {
String str = "A😊"; // 包含 Emoji
for (int i = 0; i < str.length(); ) {
int codePoint = str.codePointAt(i);
System.out.println("字符: " + str.substring(i, i + Character.charCount(codePoint))
+ " -> Unicode: " + codePoint);
i += Character.charCount(codePoint);
}
}
}
输出:
字符: A -> Unicode: 65
字符: 😊 -> Unicode: 128522方法 4:将整个字符串转换为 ASCII 码数组
public class StringToAscii {
public static void main(String[] args) {
String str = "Hello";
int[] asciiArray = new int[str.length()];
for (int i = 0; i < str.length(); i++) {
asciiArray[i] = (int) str.charAt(i);
}
System.out.println(Arrays.toString(asciiArray)); // [72, 101, 108, 108, 111]
}
}
| 方法 | 适用场景 | 注意事项 |
|---|---|---|
(int) char |
简单字符转换 | 直接获取 Unicode 码点 |
getBytes() |
字节级转换 | 默认使用平台编码(如 UTF-8) |
codePointAt() |
处理 Unicode 码点 | 适用于代理对(Emoji 等) |
| 数组存储 | 批量转换 | 结果存储在 int[] 中 |
选择方法时需考虑:
- 是否需要严格 ASCII(0-127)?
- 是否处理多字节字符(如中文)?
- 是否需要 Unicode 码点(而非字节)?

(图片来源网络,侵删)