collections 是 Python 内置的一个模块,它提供了许多非常有用的、用于替代或增强标准内建容器类型(如 dict, list, set, tuple)的特殊容器数据类型。
这些高级容器是为了解决编程中常见的问题而设计的,使用它们可以让你的代码更简洁、更高效、更易于阅读。
为什么使用 collections?
标准库中的 list, dict, set 等虽然强大,但在某些特定场景下会显得力不从心。
- 计数问题:如何高效地统计一个列表中每个元素出现的次数?用
dict可以,但代码比较繁琐。 - 队列问题:如何高效地实现一个先进先出的队列?用
list的pop(0)效率很低(O(n))。 - 字典键缺失问题:如何避免在访问字典不存在的键时抛出
KeyError?需要频繁地使用in判断或dict.get()方法。
collections 模块中的数据类型就是为了优雅地解决这些问题而生的。
核心组件详解
collections 模块中最常用的几个类包括:namedtuple, Counter, defaultdict, OrderedDict, deque, 和 ChainMap。
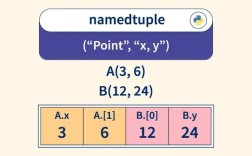
a. namedtuple - 命名元组
问题:标准的 tuple 使用索引访问元素,可读性差。person[0] 是什么?是名字还是年龄?
解决方案:namedtuple 创建了一个带有字段名的元组子类,既拥有元组的不可变性,又拥有通过名字访问的便利性。
特点:
- 不可变(像元组一样)。
- 通过属性名访问,而不是索引。
- 比普通类更节省内存。
示例:
from collections import namedtuple
# 定义一个命名元组类型 'Point',它有两个字段 'x' 和 'y'
Point = namedtuple('Point', ['x', 'y'])
# 创建一个实例
p = Point(11, y=22)
# 通过属性名访问
print(p.x) # 输出: 11
print(p.y) # 输出: 22
# 也可以像元组一样通过索引访问
print(p[0]) # 输出: 11
# 获取所有字段名
print(p._fields) # 输出: ('x', 'y')
# 转换为字典
print(p._asdict()) # 输出: {'x': 11, 'y': 22}
使用场景:当需要创建一个简单的、不可变的数据对象来存储数据时,比如数据库记录、坐标点、配置项等。
b. Counter - 计数器
问题:如何统计一个可迭代对象中每个元素出现的频率?
解决方案:Counter 是一个 dict 的子类,专门用于计数,它接收一个可迭代对象,并返回一个元素到其计数的映射。
特点:
- 继承自
dict。 - 提供了方便的计数方法,如
most_common()。 - 初始化时可以直接传入列表、字符串等。
示例:
from collections import Counter
# 统计一个列表中每个单词出现的次数
words = ['apple', 'banana', 'apple', 'orange', 'banana', 'apple']
word_counts = Counter(words)
print(word_counts)
# 输出: Counter({'apple': 3, 'banana': 2, 'orange': 1})
# 访问计数,就像访问字典一样
print(word_counts['apple']) # 输出: 3
print(word_counts['pear']) # 输出: 0 (不会报错)
# 获取最常见的 n 个元素
print(word_counts.most_common(2))
# 输出: [('apple', 3), ('banana', 2)]
# 更新计数
word_counts.update(['apple', 'grape'])
print(word_counts['apple']) # 输出: 4
使用场景:词频统计、数据分析、投票系统等任何需要计数的场景。
c. defaultdict - 默认字典
问题:当访问字典中不存在的键时,会抛出 KeyError,我们通常需要先检查键是否存在,如果不存在则初始化一个值。
解决方案:defaultdict 是 dict 的子类,它允许你在创建实例时指定一个默认的工厂函数,当访问一个不存在的键时,它会自动调用这个工厂函数来生成默认值,而不是抛出 KeyError。
特点:
- 继承自
dict。 - 在初始化时需要一个可调用对象(如
list,int,set等)作为参数。
示例:
from collections import defaultdict
# 创建一个 defaultdict,当键不存在时,会自动创建一个空列表 []
# lambda: [] 是一个返回空列表的匿名函数
d = defaultdict(lambda: [])
# 正常访问不存在的键,不会报错
d['a'].append(1)
d['a'].append(2)
d['b'].append(4)
print(d)
# 输出: defaultdict(<function <lambda> at 0x...>, {'a': [1, 2], 'b': [4]})
# 如果用普通 dict,需要这样写:
normal_dict = {}
if 'a' not in normal_dict:
normal_dict['a'] = []
normal_dict['a'].append(1)
使用场景:构建多值字典(一个键对应多个值)、图的邻接表表示、分组数据等。
d. OrderedDict - 有序字典
问题:在 Python 3.7 之前,标准的 dict 是无序的,即使你按顺序插入键值对,遍历时顺序也可能不是插入顺序。
解决方案:OrderedDict 记住键值对的插入顺序。
特点:
- 继承自
dict。 - 严格维护插入顺序。
- 在 Python 3.7+ 中,
dict已经默认是有序的,但在旧版本或需要明确表达“有序”意图时,OrderedDict仍然很有用。 - 它还有一些
dict没有的方法,如popitem(last=True),可以按 LIFO(后进先出)或 FIFO(先进先出)的顺序弹出元素。
示例:
from collections import OrderedDict
# 创建一个有序字典
od = OrderedDict()
od['a'] = 1
od['b'] = 2
od['c'] = 3
# 遍历顺序就是插入顺序
for key in od:
print(key, od[key])
# 输出:
# a 1
# b 2
# c 3
# 使用 popitem(last=False) 可以实现先进先出
od.popitem(last=False)
# 移除了 'a'
print(od) # 输出: OrderedDict([('b', 2), ('c', 3)])
使用场景:需要明确依赖键值对顺序的场景,如实现 LRU (Least Recently Used) 缓存、序列化/反序列化数据等。
e. deque - 双端队列
问题:使用 list 作为队列时,从头部弹出元素(list.pop(0))的时间复杂度是 O(n),因为列表中的所有元素都需要移动,这在大数据量时效率很低。
解决方案:deque (double-ended queue) 是一个双端队列,它从两端添加或删除元素的时间复杂度都是 O(1),效率极高。
特点:
- 类似于
list,但优化了在两端的操作。 - 线程安全,可以用于多线程环境下的生产者-消费者模型。
示例:
from collections import deque
# 创建一个 deque
d = deque(['a', 'b', 'c'])
# 从右侧添加 (append)
d.append('d')
print(d) # 输出: deque(['a', 'b', 'c', 'd'])
# 从左侧添加 (appendleft)
d.appendleft('z')
print(d) # 输出: deque(['z', 'a', 'b', 'c', 'd'])
# 从右侧弹出 (pop)
print(d.pop()) # 输出: 'd'
print(d) # 输出: deque(['z', 'a', 'b', 'c'])
# 从左侧弹出 (popleft)
print(d.popleft()) # 输出: 'z'
print(d) # 输出: deque(['a', 'b', 'c'])
使用场景:实现队列、栈、广度优先搜索等数据结构。
f. ChainMap - 链式映射
问题:如何将多个字典或映射逻辑上合并成一个,但不实际合并它们(避免内存浪费),并能够像访问一个字典一样访问它们?
解决方案:ChainMap 将多个容器对象(通常是字典)链接在一起,形成一个单一的、可更新的视图,它会按顺序查找,直到找到第一个匹配的键。
特点:
- 不会创建一个新的字典,而是保存了对原始容器的引用。
- 查找速度快,但更新操作只会影响第一个包含该键的字典。
示例:
from collections import ChainMap
# 定义两个字典
dict1 = {'a': 1, 'b': 2}
dict2 = {'b': 3, 'c': 4}
# 创建一个 ChainMap
chain = ChainMap(dict1, dict2)
# 查找 'b',会先在 dict1 中找到
print(chain['b']) # 输出: 1 (来自 dict1)
# 查找 'c',在 dict1 中找不到,会在 dict2 中找到
print(chain['c']) # 输出: 4 (来自 dict2)
# 查找 'a',只在 dict1 中有
print(chain['a']) # 输出: 1
# 更新 'a',只会更新 dict1
chain['a'] = 10
print(dict1) # 输出: {'a': 10, 'b': 2}
# 添加新键,会添加到第一个字典中
chain['d'] = 5
print(dict1) # 输出: {'a': 10, 'b': 2, 'd': 5}
使用场景:合并命令行参数、环境变量和默认配置;在多个上下文中查找变量。
总结与对比
| 容器 | 继承自 | 主要用途 | 时间复杂度 (关键操作) |
|---|---|---|---|
namedtuple |
tuple |
创建不可变、可读性高的数据结构 | 访问: O(1) |
Counter |
dict |
高效计数 | 访问/更新: O(1) |
defaultdict |
dict |
自动为不存在的键创建默认值 | 访问/更新: O(1) |
OrderedDict |
dict |
保持键值对插入顺序 | 插入/删除: O(1) |
deque |
- | 高效的两端操作 | 两端添加/删除: O(1) |
ChainMap |
collections.abc.Mapping |
逻辑上合并多个映射 | 查找: O(n) (n为字典数量) |
如何探索更多?
如果你想查看 collections 模块中还有哪些工具,可以使用 Python 的 dir() 函数或 help() 函数:
import collections # 列出 collections 模块中的所有成员 print(dir(collections)) # 查看某个特定类的帮助信息 help(collections.UserDict)
collections 模块还包含了一些更专业的工具,如 UserDict, UserList, UserString(用于自定义容器类型的基础类),以及 abc(抽象基类)等,但以上六个是最常用和最核心的。
掌握 collections 模块是提升 Python 编程能力的重要一步,它能让你的代码更加地道和高效。