+副标题,兼顾SEO与可读性) Python Collections:不止于list和dict,你必须掌握的“数据结构瑞士军刀” 从入门到精通,一文详解collections模块7个核心工具,让你的代码更优雅、更高效!**

引言(抓住用户痛点,引发共鸣)
嗨,各位Pythoner!
当我们谈论Python数据类型时,脑海中首先浮现的往往是列表(list)、字典(dict)、元组(tuple)和集合(set),它们是Python内置的“四大金刚”,日常开发中几乎无处不在,但你是否曾遇到过这样的场景:
- 需要一个默认值是0的计数器,不想每次都手动
if key in dict: ... else: ...? - 想要一个双向队列,高效地在两端进行增删操作,而不是用
list模拟导致性能低下? - 需要一个字典,但希望它的键是有序的(比如按插入顺序)?
- 想要一个集合,但允许其中的元素出现固定次数,超过自动移除?
如果你的答案是“是”,今天我要向你隆重介绍Python标准库中的宝藏模块——collections,它就像一个“数据结构的瑞士军刀”,内置了一系列高性能、功能强大的替代品和扩展,专门为了解决上述这些“小麻烦”而存在,本文将带你彻底搞懂collections模块,让你在编码时如虎添翼,写出更Pythonic、更高效的代码!
结构化、深度解析,满足不同层次用户需求)**

collections模块是Python内置的一个集合操作模块,它提供了许多有用的集合类和函数,是对Python内置数据类型的强大补充,我们通过官方文档中给出的Counter、OrderedDict等别名,来逐个深入剖析它的核心成员。
Counter:计数神器,统计元素频率
场景需求: 统计一个字符串中每个字符出现的次数,或者一个列表中每个元素出现的频率。
传统痛点: 使用dict手动遍历、判断、累加,代码繁琐且易出错。
Counter解决方案:
Counter是dict的一个子类,专门用于计数,它是一个无散列字典,其中元素被存储为字典的键,它们的计数被存储为字典的值。

代码示例:
from collections import Counter
# 统计字符串中字符频率
text = "hello world"
char_counts = Counter(text)
print(char_counts)
# 输出: Counter({'l': 3, 'o': 2, 'h': 1, 'e': 1, ' ': 1, 'w': 1, 'r': 1, 'd': 1})
# 统计列表中元素频率
numbers = [1, 2, 3, 1, 2, 1, 4, 5, 4, 1]
num_counts = Counter(numbers)
print(num_counts)
# 输出: Counter({1: 4, 2: 2, 4: 2, 3: 1, 5: 1})
# 获取最常见的N个元素
print(char_counts.most_common(2)) # 输出: [('l', 3), ('o', 2)]
核心价值:
- 简洁高效: 一行代码搞定统计,代码可读性极高。
- 功能丰富:
most_common()方法让你轻松获取高频元素。 - 数学运算: 支持加减等操作,方便进行集合的计数合并与差集计算。
defaultdict:告别KeyError,为字典设置默认值
场景需求: 创建一个字典,当访问一个不存在的键时,自动返回一个预设的默认值(如0、空列表等),而不是抛出KeyError。
传统痛点: 每次访问前都要用in判断或使用dict.get(key, default),代码冗长。
defaultdict解决方案:
defaultdict是dict的子类,它在初始化时接受一个default_factory(可调用对象),当试图访问一个不存在的键时,它会自动调用这个工厂函数来生成默认值。
代码示例:
from collections import defaultdict
# 传统方式
word_counts = {}
for word in ['apple', 'banana', 'apple', 'orange', 'banana', 'apple']:
if word not in word_counts:
word_counts[word] = 0
word_counts[word] += 1
print(word_counts)
# defaultdict方式
word_counts_dd = defaultdict(int) # int() 会返回 0
for word in ['apple', 'banana', 'apple', 'orange', 'banana', 'apple']:
word_counts_dd[word] += 1
print(word_counts_dd)
# 用于分组
groups = defaultdict(list)
data = [('a', 1), ('b', 2), ('a', 3), ('c', 4), ('b', 5)]
for key, value in data:
groups[key].append(value)
print(groups)
# 输出: defaultdict(<class 'list'>, {'a': [1, 3], 'b': [2, 5], 'c': [4]})
核心价值:
- 代码优雅: 彻底消除
if key in dict的丑陋判断。 - 逻辑清晰: 更专注于业务逻辑本身,而非底层细节。
- 性能微优: 相比
get()方法,在某些场景下性能略有优势。
OrderedDict:记住插入顺序的字典
场景需求: 需要一个字典,其元素的顺序是按照插入顺序排列的,并且在迭代时保持这个顺序。
传统痛点: 在Python 3.7之前,普通字典是无序的,即使现在,明确表达“有序”的意图也很重要。
OrderedDict解决方案:
OrderedDict会记住键值对的插入顺序,这在需要序列化(如JSON)或依赖顺序的场景中非常有用。
代码示例:
from collections import OrderedDict
# 创建有序字典
d = OrderedDict()
d['apple'] = 1
d['banana'] = 2
d['orange'] = 3
print(d)
# 输出: OrderedDict([('apple', 1), ('banana', 2), ('orange', 3)])
# 按顺序迭代
for key in d:
print(key)
# 输出: apple, banana, orange
# 移动到最后一个
d.move_to_end('apple')
print(d)
# 输出: OrderedDict([('banana', 2), ('orange', 3), ('apple', 1)])
核心价值:
- 保证顺序: 明确且可靠地维护插入顺序。
- 特殊操作:
move_to_end()等方法提供了灵活的顺序调整能力。 - 兼容性: 在需要跨版本兼容或强调顺序语义时是最佳选择。
deque:高效的双端队列
场景需求: 需要一个数据结构,可以高效地在两端进行添加和删除操作,实现一个队列或栈,特别是需要频繁操作两端时。
传统痛点: 使用list在头部进行insert(0, ...)或pop(0)操作的时间复杂度是O(n),效率极低。
deque解决方案:
deque(双端队列)是list的高效替代品,专门为在两端快速操作而设计,其两端的添加和删除操作时间复杂度均为O(1)。
代码示例:
from collections import deque
# 创建一个双端队列
d = deque(['apple', 'banana', 'cherry'])
print(d)
# 输出: deque(['apple', 'banana', 'cherry'])
# 在右侧添加
d.append('date')
print(d)
# 输出: deque(['apple', 'banana', 'cherry', 'date'])
# 在左侧添加
d.appendleft('apricot')
print(d)
# 输出: deque(['apricot', 'apple', 'banana', 'cherry', 'date'])
# 从右侧弹出
print(d.pop()) # 输出: 'date'
print(d)
# 输出: deque(['apricot', 'apple', 'banana', 'cherry'])
# 从左侧弹出
print(d.popleft()) # 输出: 'apricot'
print(d)
# 输出: deque(['apple', 'banana', 'cherry'])
核心价值:
- 性能卓越: 两端操作的速度远超
list,是构建队列和栈的理想选择。 - 内存友好: 相比
list,它在处理大量数据时内存效率更高。 - 功能全面: 提供了
rotate()(旋转)、clear()等实用方法。
ChainMap:优雅地合并多个字典
场景需求: 需要同时查询多个字典,但不想(或不能)将它们真正合并成一个,希望保持它们的独立性。
传统痛点: 手动写循环查找,或者使用{**dict1, **dict2}合并(这会创建一个新字典,开销大)。
ChainMap解决方案:
ChainMap将多个字典(或其他映射)逻辑上合并为一个视图,当你查找一个键时,它会按照字典的顺序依次查找,直到找到第一个匹配的为止,它本身不存储数据,只是引用了原始的字典。
代码示例:
from collections import ChainMap
dict1 = {'a': 1, 'b': 2}
dict2 = {'b': 3, 'c': 4, 'd': 5}
# 创建链式映射
combined = ChainMap(dict1, dict2)
print(combined)
# 输出: ChainMap({'a': 1, 'b': 2}, {'b': 3, 'c': 4, 'd': 5})
# 查找键 'b',会先在 dict1 中找到
print(combined['b']) # 输出: 2
# 查找键 'c',在 dict2 中找到
print(combined['c']) # 输出: 4
# 查找不存在的键会引发 KeyError
try:
print(combined['e'])
except KeyError as e:
print(f"KeyError: {e}")
# 新增一个字典到链的前面
dict3 = {'a': 10, 'e': 20}
combined_new = ChainMap(dict3, combined)
print(combined_new['a']) # 输出: 10 (来自 dict3)
核心价值:
- 高效合并: 无需复制数据,内存开销极小。
- 动态更新: 原始字典的修改会立即反映在
ChainMap中。 - 作用域模拟: 常用于模拟嵌套作用域,如处理命令行参数、环境变量和默认值。
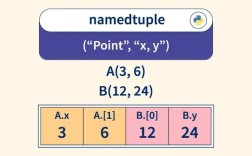
namedtuple:可读性超强的元组
场景需求: 需要一个简单的、不可变的数据结构来存储一组相关的数据,并希望像访问对象属性一样访问它们,而不是用索引。
传统痛点: 使用普通元组,访问元素时依赖索引(如person[0]),可读性差,容易出错。
namedtuple解决方案:
namedtuple是一个工厂函数,可以创建一个元组子类,并指定字段名,它兼具元组的不可变性和字典的易读性。
代码示例:
from collections import namedtuple
# 创建一个命名元组类 'Point'
Point = namedtuple('Point', ['x', 'y', 'z'])
# 创建实例
p1 = Point(10, 20, 30)
p2 = Point(5, 15, 25)
print(p1)
# 输出: Point(x=10, y=20, z=30)
# 像访问属性一样访问
print(f"X-coordinate: {p1.x}")
# 输出: X-coordinate: 10
# 像元组一样解包
x, y, z = p1
print(f"Coordinates: x={x}, y={y}, z={z}")
# 输出: Coordinates: x=10, y=20, z=30
# 检查属性
print(p1 == p2) # 输出: False
核心价值:
- 代码可读性:
person.name远胜于person[0]。 - 内存高效: 与普通对象相比,内存占用更小。
- 不可变性: 线程安全,适合存储不变的数据。
UserDict, UserList, UserList:自定义数据结构的基石
场景需求: 想要继承dict、list等内置类型,但直接继承它们可能会因为一些内置优化(如dict.__init__不接受非字符串键)而导致意想不到的问题。
传统痛点: 直接继承dict或list有时会遇到“坑”,实现起来不够直观。
UserDict/UserList/UserSet解决方案:
这三个类是相应内置类型的“包装器”,它们将内置类型的接口暴露给你,让你可以更安全、更方便地继承和重写它们的行为,它们将实际数据存储在一个名为data的普通字典/列表/集合中,避免了继承内置类时可能遇到的复杂性。
代码示例 (以UserDict为例):
from collections import UserDict
class MyDict(UserDict):
def __setitem__(self, key, value):
# 在设置值之前,将键转换为大写
super().__setitem__(str(key).upper(), value)
def popitem(self, last=True):
# 自定义popitem行为
if not self.data:
raise KeyError('dictionary is empty')
key = next(iter(self.data))
return (key, self.pop(key))
my_dict = MyDict()
my_dict['name'] = 'Alice'
my_dict['age'] = 30
print(my_dict)
# 输出: {'NAME': 'Alice', 'AGE': 30}
# 注意,键已经被转换为大写
print(my_dict['NAME']) # 输出: Alice
核心价值:
- 继承更安全: 避免了直接继承内置类的陷阱。
- 定制更灵活: 可以轻松地重写核心方法,实现自定义逻辑。
- 代码更清晰: 将你的逻辑与内置类的内部实现解耦。
总结与最佳实践
collections模块是Python标准库中的一颗明珠,它提供的工具并非炫技,而是为了解决实际开发中频繁遇到的问题,掌握它们,意味着你的代码将朝着以下方向进化:
- 更简洁: 用更少的代码表达更清晰的意思。
- 更高效: 选择最适合特定场景的数据结构,避免性能瓶颈。
- 更健壮: 减少因手动处理边界条件而引入的bug。
- 更Pythonic: 遵循Python的“优雅胜丑陋”之禅。
何时使用哪个?
| 工具 | 解决的核心问题 | 关键特性 |
|---|---|---|
| Counter | 元素计数 | most_common() |
| defaultdict | 字典默认值 | default_factory |
| OrderedDict | 记住字典顺序 | move_to_end() |
| deque | 双端高效操作 | O(1)的头部/尾部操作 |
| ChainMap | 逻辑合并多个字典 | 无数据复制,动态更新 |
| namedtuple | 可读性强的元组 | 像对象一样访问,不可变 |
| UserDict | 安全自定义字典 | 继承更简单,重写更灵活 |
最后的小建议:
不要为了用而用,在选择使用collections中的某个工具前,先问问自己:“我当前的问题,用内置类型能否优雅解决?如果不能,collections中的哪个工具是为此量身定制的?”
CTA,引导互动)
collections模块的世界远不止本文介绍的这些,它还有更多等待你去探索的角落,希望这篇文章能成为你深入理解collections模块的起点。
轮到你了!
你在日常开发中最喜欢collections中的哪个工具?或者你有什么独到的使用技巧?欢迎在评论区留言分享,我们一起交流,共同进步!
别忘了点赞和收藏,以便随时查阅哦!