(H1):Java 获取 String 编码终极指南:告别乱码,掌握字符编码的“钥匙”
Meta Description: 深入探讨 Java 如何获取 String 的编码(Charset),本文详细解析了 String.getBytes()、Charset 类、StandardCharsets 以及 CharsetDetector 等核心方法与工具,并提供实战代码,助你彻底解决 Java 开发中的乱码难题,提升代码健壮性。

引言:乱码,程序员的“永恒之痛”
“为什么我读取的文件是乱码?”
“为什么我用 POST 请求传到后端的数据是乱码?”
“为什么这个字符串在我电脑上显示正常,在服务器上就变成了问号?”
如果你是一名 Java 开发者,这些问题一定不陌生,乱码问题的根源,几乎都指向一个核心概念:字符编码,在 Java 中,一切文本的表示都离不开 String 类,而 String 内部使用的是 UTF-16 编码,当我们与外部世界(如文件、网络、数据库)交互时,这些外部数据往往使用不同的编码(如 GBK、ISO-8859-1、UTF-8)。
“Java 如何获取 String 的编码” 这个问题,本质上是在问:“如何判断一个 String 对象所代表的原始字节序列是按照哪种编码格式被转换而来的?”
这是一个看似简单却极具挑战性的问题,本文将为你拨开迷雾,提供从基础到高级的全方位解决方案。

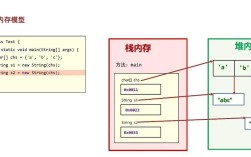
核心认知:String 本身没有“编码”属性
在深入探讨解决方案之前,我们必须建立第一个,也是最重要的认知:
在 Java 中,
String对象本身是不存储编码信息的。
String 是一个抽象的、不可变的字符序列,它内部维护着一个 char 数组,这个 char 数组使用的是 UTF-16 编码来表示每个字符,这意味着,一旦一个字节序列被解码成 String,原始的编码信息就丢失了。
打个比方:
你有一封用中文写的信(字节序列),你把它交给了翻译官(JVM),翻译官把它翻译成了通用的、所有人都懂的语言(String 对象),你问翻译官:“这封信原来是用的哪种方言(编码)?” 翻译官除了知道信的内容,对原始方言一无所知。
我们无法从一个已经存在的 String 对象中“获取”其编码,我们能做的,是在字节序列转换为 String 之前,正确地指定编码,或者在拥有原始字节序列的前提下,通过“探测”或“约定”的方式来推断其编码。
解决方案一:最佳实践——“约定优于配置”
既然无法从 String 反推编码,那么最可靠的方法就是在数据流转的源头和终点,明确地、强制地使用统一的编码,这是解决乱码问题的根本之道。
使用 StandardCharsets (Java 7+)
Java 7 引入了 StandardCharsets 类,它提供了一组预定义的字符编码常量,避免了我们手动拼写字符串(如 "UTF-8")可能带来的拼写错误。
场景:将 String 转换为 byte[] 并指定编码
import java.nio.charset.StandardCharsets;
public class StringToBytesExample {
public static void main(String[] args) {
String originalString = "你好,Java世界!";
// 使用 UTF-8 编码将 String 转换为 byte[]
// 这是推荐的做法,因为它明确了编码意图
byte[] utf8Bytes = originalString.getBytes(StandardCharsets.UTF_8);
// 同样,使用 GBK 编码
// byte[] gbkBytes = originalString.getBytes(StandardCharsets.ISO_8859_1); // 注意:ISO-8859-1 不支持中文
// 正确的 GBK 编码方式
byte[] gbkBytes = originalString.getBytes("GBK"); // 需要处理 UnsupportedEncodingException
System.out.println("UTF-8 编码后的字节长度: " + utf8Bytes.length);
System.out.println("GBK 编码后的字节长度: " + gbkBytes.length);
// 将 byte[] 用相同的编码转换回 String
String fromUtf8Bytes = new String(utf8Bytes, StandardCharsets.UTF_8);
String fromGbkBytes = new String(gbkBytes, "GBK");
System.out.println("从 UTF-8 字节恢复的字符串: " + fromUtf8Bytes);
System.out.println("从 GBK 字节恢复的字符串: " + fromGbkBytes);
}
}
关键点:
String.getBytes(Charset charset):这是将String转换为字节的推荐方法,因为它明确指定了编码。new String(byte[] bytes, Charset charset):这是将字节转换回String的推荐方法。
处理网络请求和文件 I/O
在与外部系统交互时,务必在创建 InputStreamReader 或 OutputStreamWriter 时指定编码。
文件读取示例:
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.nio.charset.StandardCharsets;
public class FileReadExample {
public static void main(String[] args) {
String filePath = "test.txt";
try (BufferedReader reader = new BufferedReader(
new InputStreamReader(new FileInputStream(filePath), StandardCharsets.UTF_8))) {
String line;
while ((line = reader.readLine()) != null) {
System.out.println(line);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
关键点: 在 InputStreamReader 的构造函数中指定 StandardCharsets.UTF_8,确保文件被正确解码。
解决方案二:亡羊补牢——“探测”未知编码
在某些情况下,你可能会接收到一个来源不明的字节流,你不知道它是什么编码,这时,我们需要借助“字符编码探测器”来猜测其编码。
使用 juniversalchardet (来自 Mozilla 的算法)
这是一个非常流行的 Java 库,它基于 Mozilla 的字符编码检测算法,能够比较准确地判断文本的编码。
添加依赖 (Maven):
<dependency>
<groupId>com.github.junrar</groupId>
<artifactId>juniversalchardet</artifactId>
<version>2.1.0</version> <!-- 请使用最新版本 -->
</dependency>
编写探测代码:
import org.mozilla.universalchardet.UniversalDetector;
import java.io.IOException;
import java.io.InputStream;
public class EncodingDetector {
public static String detectCharset(byte[] bytes) {
UniversalDetector detector = new UniversalDetector(null);
detector.handleData(bytes, 0, bytes.length);
detector.dataEnd();
String charset = detector.getDetectedCharset();
detector.reset();
return charset;
}
public static void main(String[] args) throws IOException {
// 假设我们有一个用 GBK 编码的文本文件
String filePath = "gbk_test.txt";
try (InputStream inputStream = new FileInputStream(filePath)) {
byte[] buffer = new byte[4096];
int bytesRead;
byte[] allBytes = new byte[0];
while ((bytesRead = inputStream.read(buffer)) != -1) {
byte[] newBytes = new byte[allBytes.length + bytesRead];
System.arraycopy(allBytes, 0, newBytes, 0, allBytes.length);
System.arraycopy(buffer, 0, newBytes, allBytes.length, bytesRead);
allBytes = newBytes;
}
String detectedCharset = detectCharset(allBytes);
System.out.println("探测到的编码是: " + detectedCharset);
if (detectedCharset != null) {
String content = new String(allBytes, detectedCharset);
System.out.println("用探测到的编码解码后的内容: " + content);
}
}
}
}
关键点与局限性:
- 这是一个“猜测”:不是 100% 准确,尤其是在文本很短或多种编码混合的情况下。
- 性能开销:探测过程比直接指定编码要慢。
- 用途:适用于处理用户上传的未知文件、解析不规范的邮件等“脏数据”场景,对于可控的系统,始终首选“约定优于配置”。
常见误区与“坑”
String.getBytes() 不带参数
// 危险! byte[] bytes = myString.getBytes();
这个方法会使用 JVM 的默认平台编码(file.encoding),这个编码在不同操作系统、不同 JVM 配置下可能不同(Windows 可能是 GBK,Linux 可能是 UTF-8),导致代码在 A 机器上正常,在 B 机器上乱码。
正确做法: 永远不要使用不带参数的 getBytes(),总是显式地传入 StandardCharsets.UTF_8 或其他你明确需要的编码。
ISO-8859-1 的“万能”陷阱
很多人知道 ISO-8859-1 不会造成乱码,因为它能表示 0-255 的字节,不会丢失信息,它常被用作“中间编码”来处理乱码。
// 场景:前端用 GBK 发送数据,但后端用 ISO-8859-1 读取
// String wrongString = request.getParameter("name"); // wrongString 是用 ISO-8859-1 解码 GBK 字节后的乱码
// String correctString = new String(wrongString.getBytes(StandardCharsets.ISO_8859_1), "GBK");
这确实是一种修复方法,但它治标不治本,正确的做法是直接在读取参数时就指定正确的编码(通常通过配置 Filter 实现),而不是依赖这种“回炉重造”的技巧。
总结与最佳实践
| 场景 | 推荐方案 | 核心思想 |
|---|---|---|
| 可控系统内部数据流转 | StandardCharsets.UTF_8 |
强制统一,约定优于配置,在所有 I/O 操作(文件、网络、数据库)中,明确指定 UTF-8。 |
| 处理外部未知来源的字节流 | juniversalchardet 等探测库 |
探测与猜测,作为最后的手段,用于处理无法控制来源的“脏数据”。 |
| 修复已知的乱码问题 | 使用 ISO-8859-1 作为桥梁 |
字节还原,当 A 编码被错误地用 B 编码解码后,可以用 ISO-8859-1 还原原始字节,再用正确编码解码,这是补救措施,非首选。 |
| 绝对避免 | String.getBytes() 不带参数 |
依赖平台默认编码,是导致跨环境乱码的头号元凶。 |
最终结论: “Java 获取 String 的编码”这个问题,答案并非一个简单的 API 调用,它考验的是开发者对字符编码本质的理解。真正的“获取”,是在数据产生的那一刻就“获取”并“固定”下它的编码,并在此后的整个生命周期中,像对待珍宝一样小心翼翼地使用它。
掌握这些原则和方法,你将能自信地面对并解决绝大多数与编码相关的难题,让你的 Java 应用更加健壮和可靠。
(文末可添加评论互动区,引导用户留言讨论自己遇到的编码问题) 你觉得哪种编码方案最实用?欢迎在评论区分享你的经验和看法!