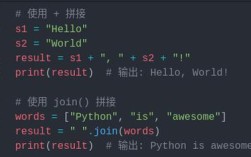
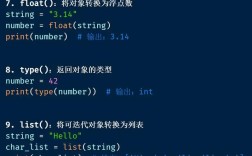
核心方法:decode()
bytes 对象有一个内置的 decode() 方法,它可以将字节串解码为字符串。

(图片来源网络,侵删)
语法:
bytes_object.decode(encoding='utf-8', errors='strict')
encoding(编码): 指定字节所使用的字符编码。这是最重要的参数,最常见的编码是'utf-8',它也是 Python 3 的默认编码,其他常见的编码还有'gbk','gb2312','latin-1','ascii'等。errors(错误处理): 指定解码时遇到错误该如何处理,默认值是'strict',即遇到无法解码的字节会抛出UnicodeDecodeError,其他可选值包括:'ignore': 忽略无法解码的字节。'replace': 将无法解码的字节替换成一个占位符(通常是 )。'backslashreplace': 将无法解码的字节替换成一个转义序列(如\xhh)。
基础用法:使用 UTF-8 编码(最常见)
UTF-8 是目前最通用的编码,可以表示世界上几乎所有的字符,如果你的数据来源是现代的 Web 应用、API 或大多数文本文件,那么它很可能就是 UTF-8 编码的。
# 定义一个 bytes 对象
# 在 Python 中,字符串前加 b 表示 bytes 类型
# 这里的 '你好' 在 UTF-8 编码下占用 6 个字节
my_bytes = b'\xe4\xbd\xa0\xe5\xa5\xbd'
# 使用默认的 UTF-8 编码进行解码
my_string = my_bytes.decode('utf-8')
print(f"原始 bytes 对象: {my_bytes}")
print(f"解码后的 string 对象: {my_string}")
print(f"类型: {type(my_string)}")
# 输出:
# 原始 bytes 对象: b'\xe4\xbd\xa0\xe5\xa5\xbd'
# 解码后的 string 对象: 你好
# 类型: <class 'str'>
处理不同编码
如果你的 bytes 数据是用其他编码(比如中文环境常用的 gbk)生成的,你必须使用相同的编码来解码,否则会出现乱码。
# 定义一个使用 gbk 编码的 bytes 对象
# '你好' 在 gbk 编码下占用 4 个字节
my_bytes_gbk = b'\xc4\xe3\xba\xc3'
# 错误示范:用 utf-8 解码 gbk 编码的字节,会产生乱码
# my_string = my_bytes_gbk.decode('utf-8') # 会报错 UnicodeDecodeError
# 正确示范:使用 gbk 编码进行解码
my_string_gbk = my_bytes_gbk.decode('gbk')
print(f"原始 GBK bytes: {my_bytes_gbk}")
print(f"用 GBK 解码后的 string: {my_string_gbk}")
print(f"类型: {type(my_string_gbk)}")
# 输出:
# 原始 GBK bytes: b'\xc4\xe3\xba\xc3'
# 用 GBK 解码后的 string: 你好
# 类型: <class 'str'>
处理解码错误
当 bytes 数据中包含损坏或不符合指定编码规则的字节时,就会发生解码错误,这时 errors 参数就派上用场了。

(图片来源网络,侵删)
# 创建一个包含无效 UTF-8 字节的 bytes 对象
# \xff 是一个无效的 UTF-8 起始字节
my_bytes_with_error = b'hello\xffworld'
# 1. 默认方式 (strict) - 会抛出异常
try:
my_bytes_with_error.decode('utf-8')
except UnicodeDecodeError as e:
print(f"使用 'strict' 模式时出错: {e}")
# 2. 忽略错误 (ignore) - 直接丢弃无效字节
decoded_ignore = my_bytes_with_error.decode('utf-8', errors='ignore')
print(f"使用 'ignore' 模式: '{decoded_ignore}'") # 输出 'helloworld'
# 3. 替换错误 (replace) - 用 � 替换无效字节
decoded_replace = my_bytes_with_error.decode('utf-8', errors='replace')
print(f"使用 'replace' 模式: '{decoded_replace}'") # 输出 'hello�world'
# 4. 反斜杠替换 (backslashreplace) - 用 \xhh 替换无效字节
decoded_backslash = my_bytes_with_error.decode('utf-8', errors='backslashreplace')
print(f"使用 'backslashreplace' 模式: '{decoded_backslash}'") # 输出 'hello\\xffworld'
从文件中读取 bytes 并转为 string
这是一个非常实用的场景,比如读取一个二进制文件(如图片、视频)或一个文本文件。
# 假设我们有一个名为 'my_data.txt' 的文件,内容是 "你好,世界!" 并以 UTF-8 编码保存
# --- 写入文件用于演示 ---
with open('my_data.txt', 'wb') as f:
f.write("你好,世界!".encode('utf-8'))
# --- 读取文件并解码 ---
# 使用 'rb' 模式打开文件,读取的是 bytes 类型
with open('my_data.txt', 'rb') as f:
file_bytes = f.read()
print(f"从文件读取的 bytes: {file_bytes}")
# 将 bytes 解码为 string
file_string = file_bytes.decode('utf-8')
print(f"解码后的 string: {file_string}")
# 输出:
# 从文件读取的 bytes: b'\xe4\xbd\xa0\xe5\xa5\xbd\xef\xbc\x8c\xe4\xb8\x96\xe7\x95\x8c\xef\xbc\x81'
# 解码后的 string: 你好,世界!
重要的最佳实践:如何确定编码?
这是一个经典难题,如果你收到的 bytes 数据没有附带任何编码信息,你很难 100% 准确地猜出它是什么编码。
以下是一些常见的策略:
- 已知来源:如果数据来自你自己的系统、API 或特定格式的文件(如 XML、JSON),编码通常在协议或标准中定义(现代 Web API 几乎总是使用 UTF-8)。
- 尝试常见编码:可以尝试用最常见的几种编码(如
'utf-8','gbk','latin-1')去解码,看哪个能成功且结果合理。'latin-1'(或'iso-8859-1')是一个“安全”的选择,因为它能解码任何 0-255 范围内的字节而不会出错(但解码结果可能不是你想要的)。 - 使用第三方库:对于非常棘手的情况,可以使用像
chardet这样的库来自动检测编码。
使用 chardet 库的示例:

(图片来源网络,侵删)
首先需要安装它:
pip install chardet
然后使用:
import chardet
unknown_bytes = b'\xe4\xbd\xa0\xe5\xa5\xbd' # 这是 UTF-8 编码的 '你好'
# 检测编码
result = chardet.detect(unknown_bytes)
print(f"检测结果: {result}")
# 检测结果告诉我们最可能的编码和置信度
# 结果: {'encoding': 'utf-8', 'confidence': 0.99...}
# 使用检测到的编码进行解码
if result['confidence'] > 0.9: # 设置一个置信度阈值
detected_string = unknown_bytes.decode(result['encoding'])
print(f"用检测到的编码解码: {detected_string}")
| 任务 | 方法 | 示例 |
|---|---|---|
| 基本转换 | 使用 decode() 方法 |
b'hello'.decode('utf-8') |
| 指定编码 | 在 decode() 中传入 encoding 参数 |
b'\xc4\xe3\xba\xc3'.decode('gbk') |
| 处理乱码 | 在 decode() 中传入 errors 参数 |
b'bad\xff'.decode('utf-8', errors='replace') |
| 从文件读取 | 以 'rb' 模式读,再用 decode() |
with open('file.txt', 'rb') as f: f.read().decode('utf-8') |
| 处理未知编码 | 使用 chardet 库检测 |
import chardet; chardet.detect(my_bytes) |
记住黄金法则: 你用来编码的字符集,必须和你用来解码的字符集完全一致,才能得到正确的字符串。