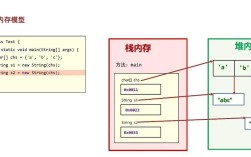
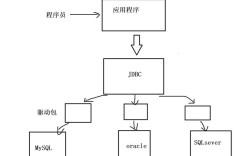
核心原理
无论使用哪种技术,文件下载的核心原理都是相通的:

(图片来源网络,侵删)
- 客户端(你的 Java 代码)向服务器发送一个 HTTP 请求,通常是一个
GET请求,请求的 URL 指向要下载的文件。 - 服务器处理请求,并将文件内容作为 HTTP 响应体返回。
- 关键在于 HTTP 响应头:
Content-Type: 告诉客户端响应体的类型(application/octet-stream表示二进制流,application/pdf表示 PDF 文件)。Content-Disposition: 这是最重要的头,它告诉浏览器如何处理响应体,当设置为attachment时,浏览器会弹出“另存为”对话框,而不是直接在页面上显示。Content-Disposition: attachment; filename="report.pdf"。Content-Length: 告诉客户端响应体的大小(字节数),这对于显示下载进度很有用。
- 客户端(Java 代码)读取 HTTP 响应体(输入流),并将其写入到本地文件系统的输出流中。
使用 HttpURLConnection (JDK 内置,无需额外依赖)
这是最基础的方式,不依赖任何第三方库,适合简单的下载任务。
示例代码
import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.URL;
public class BasicDownload {
public static void main(String[] args) {
String fileUrl = "http://example.com/path/to/your/file.zip";
String saveDir = "C:/downloads"; // Windows 示例
// String saveDir = "/home/user/downloads"; // Linux/macOS 示例
try {
downloadFile(fileUrl, saveDir);
System.out.println("文件下载成功!");
} catch (IOException e) {
System.err.println("文件下载失败: " + e.getMessage());
e.printStackTrace();
}
}
public static void downloadFile(String fileUrl, String saveDir) throws IOException {
URL url = new URL(fileUrl);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
try {
// 设置请求方法为 GET
httpConn.setRequestMethod("GET");
// 获取响应码
int responseCode = httpConn.getResponseCode();
if (responseCode == HttpURLConnection.HTTP_OK) { // 200
// 获取文件名
String fileName = getFileName(httpConn);
if (fileName == null || fileName.isEmpty()) {
// 如果响应头中没有文件名,则从 URL 中提取
fileName = fileUrl.substring(fileUrl.lastIndexOf("/") + 1);
}
// 创建保存目录(如果不存在)
File directory = new File(saveDir);
if (!directory.exists()) {
directory.mkdirs();
}
// 定义本地文件路径
String saveFilePath = saveDir + File.separator + fileName;
// 打开输入流和输出流
try (InputStream inputStream = httpConn.getInputStream();
FileOutputStream outputStream = new FileOutputStream(saveFilePath)) {
byte[] buffer = new byte[4096];
int bytesRead;
while ((bytesRead = inputStream.read(buffer)) != -1) {
outputStream.write(buffer, 0, bytesRead);
}
}
System.out.println("文件已保存至: " + saveFilePath);
} else {
System.out.println("服务器返回了非 200 响应码: " + responseCode);
}
} finally {
// 关闭连接
httpConn.disconnect();
}
}
/**
* 从 HTTP 响应头的 Content-Disposition 中提取文件名
*/
private static String getFileName(HttpURLConnection httpConn) {
String disposition = httpConn.getHeaderField("Content-Disposition");
if (disposition != null) {
// 示例: attachment; filename="filename.jpg" 或 attachment; filename*=UTF-8''filename.jpg
String[] params = disposition.split(";");
for (String param : params) {
param = param.trim();
if (param.startsWith("filename=")) {
// 处理带引号的文件名
String fileName = param.substring(9).replace("\"", "");
// 处理 RFC 5987 格式 (如 filename*=UTF-8''%E4%B8%AD%E6%96%87.txt)
if (fileName.startsWith("UTF-8''")) {
fileName = fileName.substring(7);
// 这里简化处理,实际应用中可能需要 URLDecoder
}
return fileName;
}
}
}
return null;
}
}
优缺点
- 优点:
- 无需任何外部依赖,是 JDK 自带的。
- 代码直接,易于理解底层原理。
- 缺点:
- API 较为底层,需要手动处理很多细节(如流、连接关闭、异常处理)。
- 功能有限,不支持连接池、更复杂的重试机制等。
使用 Apache HttpClient (功能强大,工业级标准)
Apache HttpClient 是目前 Java 生态中最流行、功能最全面的 HTTP 客户端库,它提供了更现代、更灵活的 API。
添加依赖 (Maven)
<dependency>
<groupId>org.apache.httpcomponents.client5</groupId>
<artifactId>httpclient5</artifactId>
<version>5.3.1</version> <!-- 请使用最新版本 -->
</dependency>
<!-- 如果需要支持 HTTPS,通常也需要这个 -->
<dependency>
<groupId>org.apache.httpcomponents.core5</groupId>
<artifactId>httpcore5</artifactId>
<version>5.2</version> <!-- 请使用最新版本 -->
</dependency>
示例代码
import org.apache.hc.client5.http.classic.methods.HttpGet;
import org.apache.hc.client5.http.impl.classic.CloseableHttpClient;
import org.apache.hc.client5.http.impl.classic.CloseableHttpResponse;
import org.apache.hc.client5.http.impl.classic.HttpClients;
import org.apache.hc.core5.http.HttpEntity;
import org.apache.hc.core5.http.io.entity.EntityUtils;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
public class HttpClientDownload {
public static void main(String[] args) {
String fileUrl = "http://example.com/path/to/your/file.zip";
String saveDir = "C:/downloads";
try (CloseableHttpClient httpClient = HttpClients.createDefault()) {
HttpGet httpGet = new HttpGet(fileUrl);
try (CloseableHttpResponse response = httpClient.execute(httpGet)) {
// 确保响应成功
if (response.getCode() == 200) {
HttpEntity entity = response.getEntity();
if (entity != null) {
// 从响应头获取文件名
String fileName = getFileNameFromResponse(response);
if (fileName == null || fileName.isEmpty()) {
fileName = fileUrl.substring(fileUrl.lastIndexOf("/") + 1);
}
File outputFile = new File(saveDir, fileName);
// 确保目录存在
outputFile.getParentFile().mkdirs();
// 使用 EntityUtils 的 consumeContent 来确保实体被完全消费和连接被释放
// 但更推荐使用流式处理,如方案三所示
try (InputStream inputStream = entity.getContent();
FileOutputStream outputStream = new FileOutputStream(outputFile)) {
byte[] buffer = new byte[4096];
int bytesRead;
while ((bytesRead = inputStream.read(buffer)) != -1) {
outputStream.write(buffer, 0, bytesRead);
}
}
System.out.println("文件下载成功: " + outputFile.getAbsolutePath());
}
} else {
System.out.println("下载失败,服务器响应码: " + response.getCode());
}
}
} catch (IOException e) {
System.err.println("下载过程中发生错误: " + e.getMessage());
e.printStackTrace();
}
}
private static String getFileNameFromResponse(CloseableHttpResponse response) {
// HttpClient 提供了更方便的头信息获取方式
return response.getFirstHeader("Content-Disposition") != null ?
response.getFirstHeader("Content-Disposition").getValue() : null;
// 后续的文件名解析逻辑与方案一相同
}
}
优缺点
- 优点:
- API 设计优秀,更符合面向对象思想。
- 功能强大:支持连接池、更精细的重试策略、拦截器、异步请求等。
- 社区活跃,文档完善,是工业级应用的首选。
- 缺点:
需要引入外部依赖。
高级实现 - 带进度条的流式下载 (推荐)
对于大文件下载,一次性将整个文件读入内存是不可取的,流式处理(边读边写)是唯一正确的方式,下面的示例结合了 Apache HttpClient 和 JavaFX 来创建一个带进度条的简单 GUI 下载器,这能很好地展示流式处理的威力。

(图片来源网络,侵删)
添加依赖 (Maven)
除了 httpclient5,还需要 JavaFX。
<!-- httpclient5 依赖同上 -->
<dependency>
<groupId>org.openjfx</groupId>
<artifactId>javafx-controls</artifactId>
<version>21</version> <!-- 请与你的 JDK 版本匹配 -->
</dependency>
<dependency>
<groupId>org.openjfx</groupId>
<artifactId>javafx-fxml</artifactId>
<version>21</version>
</dependency>
示例代码
import javafx.application.Application;
import javafx.scene.Scene;
import javafx.scene.control.Button;
import javafx.scene.control.ProgressBar;
import javafx.scene.layout.VBox;
import javafx.stage.Stage;
import org.apache.hc.client5.http.classic.methods.HttpGet;
import org.apache.hc.client5.http.impl.classic.CloseableHttpClient;
import org.apache.hc.client5.http.impl.classic.CloseableHttpResponse;
import org.apache.hc.client5.http.impl.classic.HttpClients;
import org.apache.hc.core5.http.HttpEntity;
import org.apache.hc.core5.io.Closeables;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.URL;
public class StreamDownloadWithProgress extends Application {
private ProgressBar progressBar = new ProgressBar();
private Button downloadButton = new Button("开始下载");
@Override
public void start(Stage primaryStage) {
downloadButton.setOnAction(e -> startDownload());
VBox root = new VBox(10, downloadButton, progressBar);
root.setPadding(new javafx.geometry.Insets(20));
primaryStage.setTitle("文件下载器");
primaryStage.setScene(new Scene(root, 300, 150));
primaryStage.show();
}
private void startDownload() {
downloadButton.setDisable(true);
progressBar.setProgress(0);
// 在后台线程执行下载任务,避免阻塞 UI 线程
new Thread(() -> {
String fileUrl = "http://example.com/path/to/your/large-file.zip"; // 替换为一个大文件
String saveDir = "C:/downloads";
try (CloseableHttpClient httpClient = HttpClients.createDefault()) {
HttpGet httpGet = new HttpGet(fileUrl);
try (CloseableHttpResponse response = httpClient.execute(httpGet)) {
if (response.getCode() == 200) {
HttpEntity entity = response.getEntity();
if (entity != null) {
long fileSize = entity.getContentLength();
System.out.println("文件总大小: " + fileSize + " bytes");
String fileName = getFileNameFromResponse(response);
if (fileName == null || fileName.isEmpty()) {
fileName = fileUrl.substring(fileUrl.lastIndexOf("/") + 1);
}
File outputFile = new File(saveDir, fileName);
outputFile.getParentFile().mkdirs();
long downloadedBytes = 0;
try (InputStream inputStream = entity.getContent();
FileOutputStream outputStream = new FileOutputStream(outputFile)) {
byte[] buffer = new byte[8192]; // 8KB 缓冲区
int bytesRead;
while ((bytesRead = inputStream.read(buffer)) != -1) {
outputStream.write(buffer, 0, bytesRead);
downloadedBytes += bytesRead;
// 更新进度条 (必须在 JavaFX 应用线程中执行)
final long finalDownloadedBytes = downloadedBytes;
javafx.application.Platform.runLater(() -> {
if (fileSize > 0) {
progressBar.setProgress((double) finalDownloadedBytes / fileSize);
} else {
// 如果服务器没有提供 Content-Length,则无法计算精确进度
progressBar.setProgress(-1); // 显示不确定的进度
}
});
}
}
javafx.application.Platform.runLater(() -> {
System.out.println("下载完成!");
progressBar.setProgress(1);
downloadButton.setDisable(false);
});
}
}
}
} catch (IOException e) {
javafx.application.Platform.runLater(() -> {
System.err.println("下载失败: " + e.getMessage());
progressBar.setProgress(0);
downloadButton.setDisable(false);
});
e.printStackTrace();
}
}).start();
}
private String getFileNameFromResponse(CloseableHttpResponse response) {
// ... (同方案二)
return response.getFirstHeader("Content-Disposition") != null ?
response.getFirstHeader("Content-Disposition").getValue() : null;
}
public static void main(String[] args) {
launch(args);
}
}
总结与建议
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
HttpURLConnection |
无依赖,轻量 | API 底层,功能少,需手动处理细节 | 简单的脚本、小型应用、不想引入第三方库时 |
| Apache HttpClient | 功能强大,API 优秀,工业级标准 | 需要引入外部依赖 | 绝大多数 Java Web 应用、企业级项目的首选 |
| 高级流式下载 | 内存效率高,可扩展性好(如进度条、断点续传) | 实现相对复杂 | 下载大文件、需要良好用户体验(GUI/CLI进度)的应用 |
给新手的建议:
- 如果你只是想快速实现一个简单的下载功能,方案一 (
HttpURLConnection) 足够了。 - 如果你正在开发一个正式的项目,或者预计未来会有更复杂的 HTTP 需求,强烈建议从一开始就使用方案二 (Apache HttpClient),它能为你节省大量后续开发和维护的时间。
- 方案三是方案二的进阶版,展示了如何正确地处理大文件和与 UI 交互,是实际开发中非常实用的模式。

(图片来源网络,侵删)