Of course! This is a fantastic topic that sits at the heart of big data processing. Let's break down Hadoop, Java, and HDFS, and then explore how they all work together.

The Big Picture: A Simple Analogy
Imagine you have a massive library (the HDFS - your data storage). You need to write a 100-volume encyclopedia about this library. Instead of one person trying to do it all, you hire thousands of freelance writers (the Hadoop Java programs).
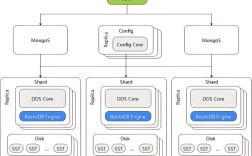
- HDFS (The Library): It's the distributed filing system. It's built to store enormous files (like the encyclopedia) across many computers (shelves). It's fault-tolerant, meaning if one shelf burns down, the encyclopedia is safe because copies exist elsewhere.
- Java (The Language & Tools): This is the language the freelance writers speak and the tools they use. It provides the vocabulary (the Hadoop API) and the rules of engagement (MapReduce, YARN) for them to coordinate their work.
- Hadoop (The Ecosystem): This is the entire project management system. It includes the library's architecture (HDFS), the project management framework (YARN), and the specific workflow methodology (MapReduce) that tells the writers how to divide up the work and combine their results.
HDFS (Hadoop Distributed File System)
HDFS is the primary storage system used by Hadoop applications. It's not like your local file system (NTFS, ext4). It's designed for a very specific purpose: storing huge files (terabytes or petabytes) reliably across a cluster of machines.
Key Characteristics of HDFS:
-
Master/Slave Architecture:
- NameNode (The Master): Manages the file system's metadata. It knows what files exist, where the blocks of those files are stored, and what permissions are in place. It's like the librarian who has the master card catalog. Crucially, it does NOT store the actual file data.
- DataNode (The Slaves): These are the worker nodes that actually store the data blocks. A file is broken into large blocks (typically 128MB or 256MB) and these blocks are distributed across multiple DataNodes. Each block is replicated (usually 3 times) for fault tolerance.
-
High Fault Tolerance: This is the most important feature. If a DataNode fails, the NameNode knows which blocks were on that node and can instruct other healthy DataNodes to replicate their copies to bring the replication factor back to the desired level. The system doesn't crash.
 (图片来源网络,侵删)
(图片来源网络,侵删) -
"Write-Once, Read-Many" (WORM): HDFS is optimized for this model. You can create a file and write data to it, but you can't change or append to it easily. This makes it perfect for storing log files, sensor data, and other kinds of big data that are generated once and then analyzed many times.
-
High Throughput for Large Files: It's designed to move large amounts of data at high speed, rather than providing low latency for small, random access requests. If you need to read a single byte from a 1TB file, it's slow. If you need to read the entire 1TB file, it's very fast.
Java (The Language and the Foundation)
Java is not just a programming language in the Hadoop world; it's the foundational technology for the Hadoop ecosystem itself.
How Java is Used:
-
Hadoop is Written in Java: The core components of Hadoop—HDFS, YARN, and the original MapReduce engine—are all written in Java. This means the entire platform runs on the Java Virtual Machine (JVM).
 (图片来源网络,侵删)
(图片来源网络,侵删) -
Developing Hadoop Applications (MapReduce): Historically, the primary way to process data on Hadoop was using the MapReduce programming model. You would write Java programs that implement two main functions:
map(key, value): This function processes a piece of input data and emits intermediate key-value pairs.reduce(key, values): This function takes all the intermediate values for a given key and aggregates them into a final output.
A developer would write these
mapandreducemethods in Java, compile the code into a JAR file, and submit it to the Hadoop cluster to run. -
The Hadoop API (Java): Hadoop provides a rich Java API that allows your application to interact with HDFS and YARN. For example, you can use Java code to:
- Connect to the HDFS cluster.
- List files in a directory.
- Read a file block by block.
- Write a new file to HDFS.
Hadoop (The Ecosystem)
Hadoop is an open-source framework for distributed storage and processing of large data sets. It's not a single program but a collection of projects. The core components are HDFS and YARN, with MapReduce being the original processing model.
Core Components:
- HDFS (Hadoop Distributed File System): As described above, the storage layer.
- YARN (Yet Another Resource Negotiator): This is the resource management layer of Hadoop. Think of it as the cluster's operating system. When you submit a Java MapReduce job (or any other type of job like Spark), YARN is responsible for:
- Scheduling: Finding the right resources (CPU, memory) on the cluster to run your job.
- Monitoring: Keeping track of the job's progress and handling any failures.
- MapReduce: The original data processing model. It's a programming paradigm that allows for massive parallelism. While largely superseded by more modern frameworks like Apache Spark for general-purpose processing, it's still a fundamental concept to understand in the Hadoop ecosystem.
Putting It All Together: A Workflow Example
Let's walk through a classic Hadoop job: "Count the frequency of each word in a massive 10TB text file stored in HDFS."
Step 1: Data Storage (HDFS)
- The 10TB file is stored in HDFS.
- The NameNode knows the file is split into ~80,000 blocks (assuming 128MB blocks).
- These blocks are distributed across, say, 100 DataNodes in the cluster. Each block is replicated 3 times.
Step 2: Job Submission (Java & YARN)
- A developer writes a Java MapReduce program. The
mapfunction will take a line of text and output(word, 1)for each word. Thereducefunction will sum up all the1s for each word. - The developer packages this Java code into a JAR file (
wordcount.jar). - They submit this JAR file to the Hadoop cluster using a command-line tool. This request goes to the YARN Resource Manager.
Step 3: Job Execution (YARN & Java)
- The Resource Manager finds a container (a slot with CPU and memory) on a suitable node in the cluster and launches an Application Master. This AM is a Java process that will manage this specific job.
- The AM requests containers from the Resource Manager to run the tasks. It needs two types of tasks:
- Map Tasks: One map task for each block of the input file.
- Reduce Tasks: A smaller number of reduce tasks (e.g., 10 or 20) to aggregate the results.
- The AM launches the map tasks on different nodes. These tasks are Java processes that read their assigned block from HDFS (from a local DataNode if possible for speed), run the
mapfunction, and write the intermediate(word, 1)pairs to local disk. - Once all map tasks are complete, the AM launches the reduce tasks. Each reduce task fetches the intermediate data it needs from the nodes where the map tasks ran.
- The reduce tasks run the
reducefunction to sum the counts. - The final output (e.g.,
(the, 4500000), (map, 1200000), etc.) is written back to an output directory in HDFS.
Step 4: Completion
- The AM reports back to the Resource Manager that the job is complete.
- The user can now read the final, much smaller output file from HDFS.
Modern Context: The Decline of Java MapReduce
It's important to note that while Java and HDFS are still fundamental, the Java MapReduce programming model is largely legacy. Today, developers almost exclusively use higher-level frameworks like Apache Spark or Apache Flink to process data on Hadoop.
- Spark is written in Scala (which runs on the JVM) and has excellent Java and Python APIs.
- Spark can read data directly from HDFS and use YARN for resource management, but it processes data in-memory, which is orders of magnitude faster than the disk-based MapReduce model.
So, the modern stack looks like this: HDFS (Storage) + YARN (Resource Management) + Spark (Processing Engine) + Java/Scala/Python (Language)
Summary Table
| Component | Role | Analogy | Key Characteristics |
|---|---|---|---|
| HDFS | Storage | The Distributed Library | - Master/Slave (NameNode/DataNode) - High Fault Tolerance (Replication) - Optimized for Large Files ("Write-Once, Read-Many") |
| Java | Language/Foundation | The Language & Tools | - Core Hadoop is written in Java. - Used to write applications (historically MapReduce). - Provides the API to interact with HDFS/YARN. |
| Hadoop | Ecosystem | The Project Management System | - An umbrella for projects. - Core: HDFS (storage) + YARN (resource manager). - Historically: MapReduce (processing model). |