这是一个非常经典的问题,尤其对于想要进入Python世界的初学者。

(图片来源网络,侵删)
核心结论:强烈建议你先学习Python基础,然后再学习Python爬虫。
把这个问题想象成盖房子:
- Python基础 地基、钢筋、水泥和砖块,没有它,你建不成任何稳固的结构。
- Python爬虫 一栋特定的房子(比如一栋别墅),你有了地基和材料,才能按照图纸(爬虫的逻辑)把它盖起来。
如果你连水泥和砖头都不会用(不懂Python语法),直接去学盖别墅(爬虫),你会发现图纸上的每一步操作(用钢筋连接”)你都无法实现,最终只会一头雾水,半途而废。
为什么必须先学Python基础?
Python爬虫是Python编程的一个应用领域,它依赖于Python的核心知识,没有扎实的基础,你寸步难行。

(图片来源网络,侵删)
语法是沟通的桥梁
爬虫的本质是编写代码,让计算机去执行任务,你需要用Python的语法(变量、循环、判断、函数等)来告诉计算机该做什么。
- 不懂基础:你连
for循环遍历一个列表、if判断语句、定义一个function都不会,如何编写循环去抓取多个网页?如何判断某个元素是否存在?
数据结构是信息的载体
爬到的数据(如标题、链接、价格)需要被存储和处理,Python的核心数据结构是基础中的基础。
- 列表:用来存储抓取到的所有链接。
- 字典:用来存储一条抓取记录,
{'title': '商品名', 'price': 99.9}。 - 集合:用于去重。
- 字符串:处理和解析网页内容的核心。
第三方库是爬虫的“武器”
爬虫离不开强大的第三方库,但使用这些库需要你理解Python的基本概念。
requests:用于发送HTTP请求,获取网页源代码,你需要理解response.text是什么(字符串),response.json()是什么(字典)。BeautifulSoup/lxml:用于解析HTML/XML文档,你需要理解如何使用它的查找方法(如find(),find_all()),这些方法返回的是什么(列表或单个元素),以及如何从中提取文本(.text)和属性(.get('href'))。pandas:用于存储和分析抓取到的结构化数据,你需要理解DataFrame和Series的概念。
错误处理是项目的保障
爬虫过程中会遇到各种意外情况:网络超时、网站结构改变、反爬虫机制等,这时就需要 try...except 错误处理机制,没有基础,你的程序会非常脆弱,动不动就崩溃。

(图片来源网络,侵删)
如何规划学习路径?(推荐路线图)
第一阶段:Python基础(约2-4周)
这个阶段的目标不是成为Python专家,而是掌握足够进行后续开发的“工具箱”。
- 环境搭建:安装Python、配置VS Code或PyCharm。
- 基本语法:
- 变量、数据类型(字符串、数字、布尔值)
- 运算符
- 数据结构(列表、元组、字典、集合)【重点】
- 控制流(
if-else,for循环,while循环)【重点】
- 函数:
- 定义和调用函数
- 参数传递
- 返回值
- 文件操作:
open(),read(),write(),close(),这是将爬取到的数据保存到本地的必备技能。
- 面向对象编程(OOP)初步了解:
- 理解
class和object的概念,不要求精通,但知道类可以帮你更好地组织爬虫代码。
- 理解
第二阶段:Python爬虫入门(约2-4周)
有了第一阶段的基础,你现在可以开始“盖房子”了。
- 了解HTTP协议:知道什么是请求、响应,GET和POST的区别,URL是什么。
- 学习
requests库:- 发送GET/POST请求。
- 处理响应内容(
text,json)。 - 设置请求头(
headers),模拟浏览器,这是反爬的第一步。
- 学习解析库(
BeautifulSoup或lxml):- 安装和基本使用。
- 掌握CSS选择器或XPath来精准定位网页元素。
- 提取文本和属性。
- 实战第一个小项目:
- 目标:抓取某个静态网站(如豆瓣电影Top250)的标题、评分和一句话简介。
- 流程:用
requests获取页面 -> 用BeautifulSoup解析 -> 用循环和列表存储数据 -> 用文件操作(如csv模块)保存到本地。
- 进阶爬虫技术:
- 动态网页处理:学习
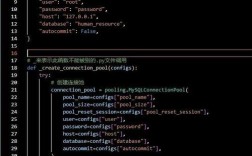
Selenium或Playwright,模拟浏览器操作,抓取JavaScript渲染的页面。 - 数据存储:学习将数据存入
MySQL或MongoDB等数据库。 - 反爬虫应对:处理验证码、IP代理池、设置请求间隔等。
- 动态网页处理:学习
总结对比
| 特性 | 先学Python基础 | 先学Python爬虫 |
|---|---|---|
| 学习曲线 | 平缓,循序渐进 | 陡峭,容易受挫 |
| 知识深度 | 扎实,理解底层逻辑 | 浅薄,知其然不知其所以然 |
| 项目能力 | 强,可胜任各种Python开发 | 弱,仅限于特定爬虫场景 |
| 长期发展 | 路径宽广(数据分析、Web开发、自动化等) | 路径相对狭窄 |
| 成就感 | 初期成就感低,但后期稳步提升 | 初期可能快速获得“成果”,但容易卡在复杂问题上 |
给你的最终建议:
耐心一点,先把Python基础打牢。 这段时间的投资会让你在后续的学习和工作中获得巨大的回报,当你掌握了基础后,你会发现爬虫的很多概念其实都只是基础知识的组合应用,学习起来会非常快,而且能写出更健壮、更高效的代码。
祝你学习顺利!