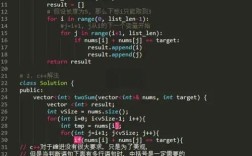
- 如何发送包含中文的请求(在 URL 参数或 POST 数据中)。
- 如何正确地解码从服务器获取的、包含中文的响应内容。
核心问题:URL 编码 和 字符编码
在计算机中,URL 和网络传输只能使用 ASCII 字符集中的字符,像中文这样的非 ASCII 字符,必须被转换成一种安全的格式,这个过程就是 URL 编码(或称百分号编码)。

空格会被编码成%20中会被编码成%E4%B8%AD文会被编码成%E6%96%87
同样,从服务器返回的网页数据(HTML、JSON 等)本身也是一串字节流,我们需要用正确的 字符编码(如 UTF-8, GBK)将这些字节流转换成我们能读懂的字符串。
发送包含中文的请求
当你需要在 URL 的查询参数或 POST 请求体中包含中文时,必须先进行 URL 编码,Python 的 urllib.parse 模块提供了 quote 和 urlencode 函数来方便地完成这个任务。
示例1:在 URL 查询参数中添加中文
假设我们要搜索关键词 "Python 中文"。
错误的做法(直接拼接):

from urllib.request import urlopen
keyword = "Python 中文"
# 直接拼接,URL是非法的,会报错或无法正确识别
url = f"http://httpbin.org/get?keyword={keyword}"
# 这里的 httpbin.org 会返回你请求的 URL,方便我们查看
这样拼接的 URL 可能会是 http://httpbin.org/get?keyword=Python 中文,其中包含空格和非 ASCII 字符,很多服务器无法正确解析。
正确的做法(使用 urllib.parse.quote):
from urllib.request import urlopen
from urllib.parse import quote
keyword = "Python 中文"
# 对中文和空格进行 URL 编码
encoded_keyword = quote(keyword) # 编码后为 'Python%20%E4%B8%AD%E6%96%87'
url = f"http://httpbin.org/get?keyword={encoded_keyword}"
print(f"编码后的 URL: {url}")
# 发送请求
response = urlopen(url)
# 读取响应内容 (bytes)
html_bytes = response.read()
# 解码响应内容 (这里 httpbin.org 默认返回 UTF-8 编码的 JSON)
html_str = html_bytes.decode('utf-8')
print(html_str)
输出:
编码后的 URL: http://httpbin.org/get?keyword=Python%20%E4%B8%AD%E6%96%87
{
"args": {
"keyword": "Python 中文"
},
"headers": {
"Accept-Encoding": "identity",
"Host": "httpbin.org",
"User-Agent": "Python-urllib/3.10",
"X-Amzn-Trace-Id": "Root=..."
},
"origin": "你的IP地址",
"url": "http://httpbin.org/get?keyword=Python%20%E4%B8%AD%E6%96%87"
}可以看到,httpbin.org 正确地解码了 keyword 参数,并返回了原始的中文值 "Python 中文"。

示例2:在 POST 请求体中发送中文表单数据
from urllib.request import Request, urlopen
from urllib.parse import urlencode
# 要发送的表单数据
data = {
'username': '张三',
'comment': '你好,世界!'
}
# 将字典编码成 application/x-www-form-urlencoded 格式的字节流
# 注意:urlencode 会自动对字典的值进行 URL 编码
encoded_data = urlencode(data).encode('utf-8')
url = 'http://httpbin.org/post'
# 创建请求对象,可以指定请求方法为 POST
request = Request(url, data=encoded_data, method='POST')
# 发送请求
response = urlopen(request)
html_bytes = response.read()
html_str = html_bytes.decode('utf-8')
print(html_str)
输出(部分):
{
"form": {
"comment": "你好,世界!",
"username": "张三"
},
...
}
可以看到,POST 的表单数据也被正确地发送和接收了。
解码包含中文的响应内容
从服务器返回的数据是字节流(bytes),直接打印会看到一堆乱码,因为你不知道它原本的字符编码是什么。
解决步骤:
- 读取字节流:使用
response.read()。 - 探测或指定字符编码:
- 最佳实践:从 HTTP 响应头中获取
Content-Type字段,它通常会指定字符编码,Content-Type: text/html; charset=utf-8。 - 备用方案:如果响应头没有指定,可以尝试猜测(很多中文网站使用
GBK编码)。
- 最佳实践:从 HTTP 响应头中获取
- 解码字节流:使用
bytes.decode()方法,将字节流转换成字符串。
示例:从不同编码的网站获取内容
from urllib.request import urlopen
import json
def fetch_and_decode(url, charset='utf-8'):
"""获取并解码 URL 内容"""
try:
response = urlopen(url)
# 获取响应头中的 Content-Type
content_type = response.headers.get('Content-Type', '')
print(f"原始响应头 Content-Type: {content_type}")
# 从 Content-Type 中提取 charset
# 'text/html; charset=gbk'
if 'charset=' in content_type:
# 更新编码为响应头中指定的编码
charset = content_type.split('charset=')[-1]
print(f"从响应头提取到编码: {charset}")
# 读取字节流
html_bytes = response.read()
# 使用指定的编码进行解码
html_str = html_bytes.decode(charset)
return html_str
except UnicodeDecodeError:
print(f"使用编码 '{charset}' 解码失败,尝试其他编码...")
# 如果指定编码失败,可以尝试其他常见编码
try:
html_str = html_bytes.decode('gbk')
return html_str
except UnicodeDecodeError:
print("GBK 解码也失败了,无法解码内容。")
return None
except Exception as e:
print(f"发生错误: {e}")
return None
# --- 测试 ---
# 1. 一个 UTF-8 编码的网站 (httpbin.org 返回 JSON)
print("--- 测试 UTF-8 ---")
url_utf8 = 'http://httpbin.org/get?name=测试'
content_utf8 = fetch_and_decode(url_utf8)
if content_utf8:
# 解析 JSON 以便更清晰地查看
data = json.loads(content_utf8)
print(f"成功获取 name 参数: {data['args']['name']}")
print("\n" + "="*40 + "\n")
# 2. 一个 GBK 编码的网站 (这里用 httpbin.org 模拟,实际需要找真实GBK网站)
# 我们手动构造一个 GBK 编码的响应来演示
print("--- 测试 GBK ---")
# 创建一个模拟的 GBK 编码的响应
gbk_text = "你好,世界!This is a test."
gbk_bytes = gbk_text.encode('gbk')
# 创建一个模拟的响应头
from http.client import HTTPMessage
headers = HTTPMessage()
headers.add_header('Content-Type', 'text/html; charset=gbk')
# 我们无法直接修改 urlopen 的响应头,所以这里用字符串模拟
# 实际爬虫中,你需要分析真实网站的响应头
# 假设我们知道了这是一个 GBK 网站并手动指定
url_gbk = 'http://httpbin.org/encoding/utf8' # 这个 URL 实际是 UTF-8,我们假装它是 GBK
# 为了演示,我们直接使用我们编码的字节
# 在真实场景中,你通过 urlopen(url_gbk).read() 得到 gbk_bytes
content_gbk = fetch_and_decode(url_gbk, charset='gbk') # 手动指定编码
if content_gbk:
print(f"成功解码 GBK 内容: {content_gbk}")
更健壮的实践: 在实际爬虫中,通常的流程是:
- 用
urlopen获取response对象。 - 从
response.headers.get('Content-Type')中提取charset。 - 如果提取到了
charset,就用它来解码response.read()。 - 如果没有提取到,可以先用
utf-8尝试解码,如果失败,再尝试gbk、gb2312等中文常见编码。
总结与最佳实践
-
发送请求时:
- URL 参数:使用
urllib.parse.quote()对非 ASCII 字符进行编码。 - POST 数据:使用
urllib.parse.urlencode()将字典数据编码成application/x-www-form-urlencoded格式的字节流,它会自动处理编码。
- URL 参数:使用
-
接收响应时:
- 首选:从
response.headers['Content-Type']中获取charset,并用它来解码response.read()。 - 备用:如果响应头没有
charset,可以先尝试utf-8,失败后再尝试gbk。 - 解码:始终使用
bytes.decode('charset_name')将字节流转换为字符串。
- 首选:从
-
推荐:对于更复杂的网络请求(如处理 Cookie、Session、自定义 Headers),建议使用更强大的第三方库,如
requests。requests库能更智能地处理编码问题,让开发者更专注于业务逻辑。
requests 示例(对比):
import requests
# 发送 GET 请求,requests 会自动对 URL 中的中文进行编码
response = requests.get('http://httpbin.org/get', params={'keyword': 'Python 中文'})
# 获取响应内容,requests 会自动根据响应头的 Content-Type 进行解码
# 你可以直接得到一个字符串
print(response.text)
# 也可以获取 JSON 数据,requests 会自动解析
print(response.json()['args']['keyword'])
可以看到,requests 库极大地简化了这些操作。