MySQL DBA 全景式教程
第一部分:角色认知与基础准备
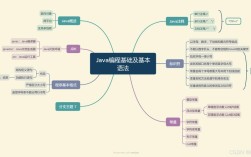
在开始学习之前,我们需要明确 DBA 是做什么的,以及需要具备哪些基础知识。

(图片来源网络,侵删)
什么是 MySQL DBA? 数据库管理员是负责数据库系统的安装、配置、监控、性能优化、备份与恢复、安全管理以及高可用架构设计和维护的专业人员,DBA 是确保数据安全、稳定、高效运行的核心角色。
DBA 的核心职责
- 日常运维: 监控数据库状态、处理告警、管理用户和权限。
- 性能优化: 识别并解决性能瓶颈,优化 SQL 查询和数据库配置。
- 高可用与容灾: 设计和维护主从复制、集群等高可用架构,制定并演练灾难恢复计划。
- 备份与恢复: 制定备份策略,并能在数据损坏或丢失时成功恢复数据。
- 安全管理: 实施数据库安全策略,防止数据泄露和未授权访问。
- 自动化与工具开发: 使用脚本(如 Shell, Python)和工具(如 Prometheus, Grafana)实现运维自动化。
前置知识要求
- Linux 基础: DBA 的工作主要在 Linux 环境下进行,你需要熟练掌握:
- 常用命令 (
ls,cd,grep,find,ps,top,netstat) - 文本编辑器 (
vi/vim) - 用户和权限管理 (
useradd,chmod) - Shell 脚本编程基础
- 系统服务管理 (
systemd)
- 常用命令 (
- 网络基础: 理解 TCP/IP、端口、防火墙等基本概念。
- SQL 基础: 精通增删改查、索引、事务、存储过程等。
第二部分:MySQL 核心概念与架构
深入理解 MySQL 的工作原理是成为 DBA 的第一步。

(图片来源网络,侵删)
MySQL 逻辑架构
- 连接层: 处理客户端连接、认证、安全。
- 服务层 (核心):
- 查询解析器: 解析 SQL 语句。
- 查询优化器: 制定最优的执行计划。
- 缓存: 缓存执行过的查询结果(MySQL 8.0 已移除,由应用层缓存替代)。
- 存储引擎接口: 统一的 API,与底层的存储引擎交互。
- 存储引擎层: 负责数据的存储和提取。这是 DBA 必须精通的部分!
- InnoDB (默认): 支持事务、行级锁、外键,是 OLTP(在线事务处理)场景的首选。
- MyISAM: 不支持事务,表级锁,读取性能好,但写入性能差,适用于 OLAP(在线分析处理)场景。
- Memory: 数据存储在内存中,重启后丢失,适用于临时表或缓存。
- Archive: 用于存储大量不常访问的归档数据,压缩率高,但只支持
SELECT和INSERT。
存储引擎 InnoDB 深入
- 聚簇索引: InnoDB 表数据文件本身就是索引(B+树)的结构,主键索引的叶子节点存储了整行数据,非主键索引的叶子节点存储的是主键值。
- 二级索引: 也叫非聚簇索引,叶子节点存储的是主键值。
- MVCC (多版本并发控制): 实现高并发读的核心技术,通过 undo log 为每个事务创建数据快照,实现了读不加锁。
- 事务 ACID 特性:
- 原子性: 事务内的操作要么全部成功,要么全部失败。
- 一致性: 事务从一个一致性状态转移到另一个一致性状态。
- 隔离性: 多个事务之间是相互隔离的。
- 持久性: 事务一旦提交,其结果就是永久性的。
- 事务隔离级别:
READ UNCOMMITTED,READ COMMITTED,REPEATABLE READ(MySQL 默认),SERIALIZABLE。
日志系统
- Redo Log (重做日志): 记录数据页的物理修改,用于 crash-safe,保证事务的持久性。
innodb_flush_log_at_trx_commit参数控制其刷盘时机。 - Undo Log (撤销日志): 记录数据被修改前的值,用于实现 MVCC 和事务回滚。
- Binlog (二进制日志): 记录所有更改数据库的 SQL 语句(基于行或语句),用于主从复制和时间点恢复。
sync_binlog参数控制其刷盘时机。 - Error Log: 记录 MySQL 启动、运行、关闭时的错误信息。
- Slow Query Log: 记录执行时间超过
long_query_time秒的 SQL 语句,是性能优化的金矿。
第三部分:安装与配置
安装 MySQL

(图片来源网络,侵删)
- 推荐方式: 使用操作系统的包管理器(如
apt,yum)或官方的 APT/YUM 仓库,便于管理和升级。 - 源码编译: 适用于特殊需求,但过程复杂,不推荐新手使用。
- 二进制包: 解压即用,适合快速部署和测试。
初始化与安全配置
- 运行
mysql_secure_installation脚本,它会引导你:- 设置 root 密码。
- 移除匿名用户。
- 禁止 root 远程登录。
- 移除测试数据库。
- 重新加载权限表。
核心配置文件 /etc/my.cnf
这是 DBA 最重要的工作文件之一,你需要熟悉以下关键参数:
[mysqld]部分:port: 端口号。datadir: 数据文件存储目录。socket: socket 文件路径。pid-file: 进程 ID 文件路径。default-storage-engine: 默认存储引擎。character-set-server: 服务器默认字符集,强烈推荐utf8mb4。collation-server: 默认排序规则。max_connections: 最大连接数。innodb_buffer_pool_size: 最重要的性能参数,通常设置为系统内存的 50%-80%。innodb_log_file_size: Redo Log 文件大小,影响事务提交性能。slow_query_log: 是否开启慢查询日志。long_query_time: 慢查询阈值(秒)。log_bin: 是否开启二进制日志。server-id: 在主从复制中必须唯一。
第四部分:日常运维与管理
用户与权限管理
-- 创建用户 CREATE USER 'app_user'@'192.168.1.%' IDENTIFIED BY 'StrongPassword!'; -- 授予权限 GRANT SELECT, INSERT, UPDATE ON mydb.* TO 'app_user'@'192.168.1.%'; -- 刷新权限使生效 FLUSH PRIVILEGES; -- 查看用户权限 SHOW GRANTS FOR 'app_user'@'192.168.1.%';
备份与恢复 这是 DBA 的生命线,必须精通!
-
备份类型:
- 物理备份: 直接复制数据文件(
.ibd,.frm),工具:Percona XtraBackup(热备,推荐)。 - 逻辑备份: 备份 SQL 语句,工具:
mysqldump(最常用)。
- 物理备份: 直接复制数据文件(
-
备份策略:
- 全量备份: 备份所有数据。
- 增量备份: 备份自上次备份以来发生变化的数据(依赖 XtraBackup)。
- 二进制日志备份: 结合全量备份和 binlog,可以实现时间点恢复。
-
实践演练:
-
使用
mysqldump备份:# 备份单个数据库 mysqldump -u root -p mydb > mydb_backup.sql # 备份所有数据库 mysqldump -u root -p --all-databases > all_db_backup.sql # 跳过锁表,适用于 InnoDB mysqldump -u root -p --single-transaction mydb > mydb_backup.sql
-
恢复:
# 恢复数据库 mysql -u root -p mydb < mydb_backup.sql
-
性能监控与优化
- 监控指标:
- QPS (Queries Per Second): 每秒查询数。
- TPS (Transactions Per Second): 每秒事务数。
- 慢查询数量。
- 连接数使用情况。
- InnoDB 缓冲池命中率。
- 核心工具:
SHOW命令:SHOW STATUS; -- 查看服务器状态变量 SHOW VARIABLES; -- 查看服务器配置变量 SHOW PROCESSLIST; -- 查看当前连接 SHOW ENGINE INNODB STATUS; -- 查看InnoDB引擎状态,非常强大!
EXPLAIN命令: 分析 SQL 查询的执行计划,是 SQL 优化的核心。EXPLAIN SELECT * FROM users WHERE id = 1;
关注
type(访问类型,ref>range>index>ALL)、key(是否使用索引)、rows(扫描行数)。- 慢查询日志分析工具:
mysqldumpslow,pt-query-digest(Percona Toolkit)。
- 优化手段:
- 索引优化: 为
WHERE,JOIN,ORDER BY涉及的列创建合适的索引。 - SQL 优化: 重写低效的 SQL,避免
SELECT *,合理使用JOIN。 - 配置优化: 调整
innodb_buffer_pool_size,innodb_log_file_size等参数。 - 架构优化: 读写分离、分库分表。
- 索引优化: 为
第五部分:高可用架构
这是中高级 DBA 的核心技能,确保服务不中断。
主从复制
- 原理: Master 将数据变更记录到 Binlog,Slave 的 I/O 线程读取 Binlog 并写入 Relay Log,SQL 线程 Relay Log 并应用到自身数据库。
- 配置步骤:
- Master: 开启
log_bin,配置server-id,创建用于复制的用户并授权。 - Slave: 配置唯一的
server-id。 - Slave: 执行
CHANGE REPLICATION SOURCE TO(MySQL 8.0+) 或CHANGE MASTER TO(旧版本) 命令,指定 Master 的地址、用户、密码和 Binlog 位置。 - Slave: 执行
START REPLICA启动复制。
- Master: 开启
- 复制模型: 异步复制、半同步复制 (插件实现)、组复制 (MySQL 8.0+)。
主主复制
- 原理: 两台互为主从,但通常需要业务层解决自增主键冲突问题(如奇偶分配),或使用全局唯一 ID 生成器,架构复杂,维护成本高,需谨慎使用。
MHA (Master High Availability)
- 简介: 一套优秀的 MySQL 高可用管理和故障切换工具,能在主库故障时,自动将最新数据的主从库提升为主库,并修复其他从库。
- 组件:
manager(管理节点),node(数据节点)。
InnoDB Cluster (MySQL Group Replication)
- 简介: MySQL 官方提供的原生高可用、高一致性解决方案,基于 Paxos 算法的组复制,提供多主模式(推荐单主)、自动故障转移。
- 组件: MySQL Shell, MySQL Router。
- 优点: 官方支持,架构简单,数据一致性高,是未来的趋势。
第六部分:进阶与最佳实践
MySQL 8.0 新特性
- 窗口函数:
ROW_NUMBER(),RANK(),LEAD(),LAG()等,极大简化复杂查询。 - CTE (Common Table Expressions):
WITH子句,提高 SQL 可读性。 - 资源组: 限制用户或查询使用的 CPU 资源。
- 直方图: 优化器统计信息,帮助选择更优的执行计划。
- 不可见索引: 可以在不删除索引的情况下使其对优化器不可见,用于调试。
分库分表
- 场景: 当单表数据量达到千万甚至亿级别,或写入压力巨大时,单库单表已无法满足需求。
- 分片策略:
- 垂直分片: 按业务拆分,将不同业务表拆分到不同数据库。
- 水平分片: 按数据行拆分,将同一张表的数据拆分到多个数据库实例中,常用哈希或范围分片。
- 挑战: 跨库事务、跨库 JOIN、全局唯一 ID。
自动化运维
- 使用 Python 或 Shell 编写脚本,实现:
- 自动备份。
- 自动监控告警(通过邮件、钉钉、企业微信)。
- 自动巡检。
- 学习使用成熟的运维平台:
- Prometheus + Grafana: 监控指标收集与可视化。
- MySQL Shell: 用于管理 InnoDB Cluster。
- Percona Toolkit: 一套强大的 MySQL 命令行工具集。
学习路径与资源推荐
学习路径
- 打好基础: 熟练掌握 Linux 和 SQL。
- 安装入门: 在虚拟机中安装 MySQL,熟悉基本操作和配置文件。
- 深入核心: 深入学习存储引擎、事务、日志系统。
- 掌握运维: 精通用户管理、备份恢复、
EXPLAIN分析。 - 攻克高可用: 动手搭建主从复制,并学习 MHA 或 InnoDB Cluster。
- 持续进阶: 关注 MySQL 8.0 新特性,学习分库分表和自动化。
推荐书籍
- 《高性能 MySQL》 (High Performance MySQL): DBA 圣经,必读!
- 《MySQL 技术内幕:InnoDB 存储引擎》: 深入理解 InnoDB 的不二之选。
- 《MySQL 实战》 (MySQL Cookbook): 包含大量实用案例和解决方案。
官方文档
- MySQL 官方文档: 最权威、最准确的信息来源,遇到问题首先查阅文档。
在线资源
- Percona Blog: 大量高质量的技术文章。
- MySQL Server Team Blog: 官方团队博客,了解最新动态和设计思路。
- 掘金、思否、CSDN: 搜索特定问题,有很多实践分享。
实践环境
- 虚拟机: 使用 VMware 或 VirtualBox 搭建多台虚拟机进行实验。
- Docker: 快速、干净地部署 MySQL 环境,非常适合学习和测试。
也是最重要的建议:
- 动手,动手,再动手! 理论知识必须通过实践来巩固,不要害怕搞坏环境,虚拟机是最好的试验田。
- 学会阅读错误日志。 大部分问题都能在日志中找到线索。
- 保持好奇心和持续学习的热情。 数据库技术发展很快,要不断跟进新版本和新特性。
祝你学习顺利,早日成为一名优秀的 MySQL DBA!