String 类在 Java 中不仅仅是一个简单的字符序列,它是一个设计精良、功能强大且经过高度优化的类。

(图片来源网络,侵删)
String 类的核心特性
在深入实现细节之前,我们先要理解 String 的几个最核心的特性:
- 不可变性:这是
String类最重要的特性,一旦一个String对象被创建,它的内容就不能被改变,任何看起来修改String的操作(如substring,replace,concat等)实际上都是创建了一个新的String对象,而原始对象保持不变。 final类:String类被声明为final,这意味着它不能被继承,这保证了String的行为不会被任何子类改变,从而维护了其不变性。- 字符数组存储:在 Java 9 之前,
String内部使用private final char[] value数组来存储字符,从 Java 9 开始,为了节省内存,改用了byte[]数组,并引入了coder字段来区分是 Latin-1 字符还是 UTF-16 编码。 - 常量池优化:Java 为了提高性能和减少内存消耗,引入了字符串常量池,这是一个特殊的内存区域,专门用于存储字符串字面量。
String 类的内部结构 (以 Java 9+ 为例)
我们来看一下 String 类的源码(简化版):
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
// @Stable 是一个注解,表示这个引用在构造后不会再改变
@Stable
private final byte[] value;
private final byte coder; // 用于标识编码: LATIN1 (0) 或 UTF16 (1)
// ... 其他字段和方法 ...
}
关键字段解析:
-
private final byte[] value:- 这是存储字符串实际内容的数组。
- 使用
byte[]而不是char[]是一个重要的优化,对于大部分只包含 ASCII 字符(Latin-1)的字符串,每个字符只需要一个字节存储,而char[]需要两个字节,这能节省 50% 的内存。 final关键字确保了value引用本身不能被修改,从而保证了String的不可变性。
-
private final byte coder: (图片来源网络,侵删)
(图片来源网络,侵删)- 这个字段是一个标志位,用于指示
value数组中的编码方式。 static final byte LATIN1 = 0;static final byte UTF16 = 1;- 如果字符串中所有字符都可以用 Latin-1(单字节)表示,
coder0,value数组就是byte[]。 - 如果字符串中包含无法用 Latin-1 表示的字符(如中文、表情符号等),
coder1,value数组在逻辑上会被当作char[]使用(每个字符占两个字节)。
- 这个字段是一个标志位,用于指示
不可变性是如何实现的?
String 的不可变性由以下几个因素共同保证:
- 类声明为
final:public final class String,这阻止了任何人通过继承来覆盖其方法并改变其行为。 - 内部存储数组为
final:private final byte[] value,这确保了value引用一旦指向一个数组,就不能再指向另一个数组。 - 没有提供修改
value数组内容的方法:String类没有提供任何public方法来直接修改value数组中的元素,所有修改操作都是“只读”的。
举例说明不可变性:
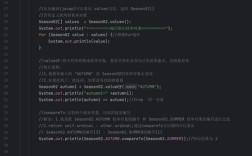
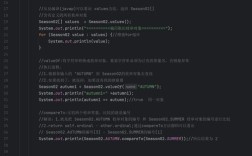
String s1 = "hello";
String s2 = s1.concat(" world"); // concat() 方法看起来修改了字符串
System.out.println(s1); // 输出: hello
System.out.println(s2); // 输出: hello world
s1指向内存中一个值为 "hello" 的String对象。- 当调用
s1.concat(" world")时,concat方法并不会修改s1指向的对象。 - 相反,它会创建一个全新的
String对象,内容为 "hello world",然后将这个新对象的引用赋值给s2。 s1仍然指向原来的 "hello" 对象。
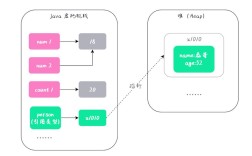
字符串常量池
字符串常量池是 JVM 的一块特殊内存区,用于存储字符串字面量,它的主要目的是避免重复创建相同内容的字符串对象,从而节省内存。
工作原理:
- 字面量创建:当代码中使用双引号 创建字符串时,JVM 首先会检查常量池中是否已经存在一个内容相同的字符串。
- 如果存在,则直接返回池中对象的引用。
- 如果不存在,则在池中创建一个新的字符串对象,并返回其引用。
String s1 = "hello"; // JVM 在常量池中创建 "hello" 对象,s1 指向它 String s2 = "hello"; // JVM 发现池中已有 "hello",直接将 s2 指向同一个对象 System.out.println(s1 == s2); // 输出: true (s1 和 s2 是同一个对象的引用)
new关键字创建:使用new关键字创建字符串时,JVM 会在堆内存中强制创建一个新的对象,不会检查常量池。
String s3 = new String("hello"); // 在堆中创建一个新的 "hello" 对象
String s4 = new String("hello"); // 再在堆中创建另一个新的 "hello" 对象
System.out.println(s1 == s3); // 输出: false (s1 在池中,s3 在堆中)
System.out.println(s3 == s4); // 输出: false (s3 和 s4 是堆中两个不同的对象)
intern() 方法:
intern() 方法是一个可以手动操作字符串常量池的方法。
- 当调用一个字符串的
intern()方法时,JVM 会检查常量池。 - 如果池中已经存在一个与该字符串内容相等的字符串,则返回池中的字符串引用。
- 如果不存在,则将该字符串对象的内容复制到常量池中,并返回池中这个新对象的引用。
String s5 = new String("hello");
s5 = s5.intern(); // s5 现在指向常量池中的 "hello"
System.out.println(s1 == s5); // 输出: true (s5 通过 intern() 指向了池中的对象)
常用方法实现原理
String 类提供了大量方法,但它们都遵循“不可变”原则。

(图片来源网络,侵删)
-
substring(int beginIndex, int endIndex):- 它不会复制原始字符数组,而是创建一个新的
String对象,这个新对象的value数组共享了原始对象的value数组,只是通过offset和count(Java 9 之前) 或coder和value的索引范围来表示子串。 - 注意: 这种共享可能会导致内存泄漏,如果一个非常大的字符串只截取了很小的一部分,那么原始大字符串因为被这个子串引用,无法被 GC 回收,这个问题在 Java 7u6 之后得到改善,
substring方法会复制一个新的字符数组。
- 它不会复制原始字符数组,而是创建一个新的
-
concat(String str):- 首先计算新字符串的总长度。
- 创建一个新的
char[](或byte[]) 数组,长度为总长度。 - 将当前字符串的内容复制到新数组的前半部分。
- 将参数
str的内容复制到新数组的后半部分。 - 最后用这个新数组创建一个新的
String对象并返回。
-
replace(char oldChar, char newChar):- 遍历原始字符串的字符数组,检查每个字符。
- 如果发现某个字符等于
oldChar,就在新数组中写入newChar,否则写入原字符。 - 如果没有任何字符被替换,为了性能,它会直接返回原始字符串对象(因为内容没变)。
- 如果有字符被替换,则创建一个新数组,生成新的
String对象。
-
split(String regex):- 使用给定的正则表达式作为分隔符来分割字符串。
- 它内部会使用正则表达式引擎来查找所有匹配的位置。
- 然后根据这些位置,从原始字符串中提取子串,并将这些子串放入一个
String[]数组中返回。
性能影响与最佳实践
String 的不可性带来了很多好处,但也需要我们在使用时注意性能问题。
最佳实践:
-
使用
StringBuilder或StringBuffer进行字符串拼接: 在循环中频繁拼接字符串时,每次拼接都会创建新对象,导致大量内存分配和 GC 压力。StringBuilder: 线程不安全,性能更高。在绝大多数单线程场景下应使用它。StringBuffer: 线程安全,方法大多有synchronized修饰,性能较低。
// 不好的做法 String result = ""; for (int i = 0; i < 1000; i++) { result += "a"; // 每次循环都创建新对象 } // 好的做法 StringBuilder sb = new StringBuilder(); for (int i = 0; i < 1000; i++) { sb.append("a"); // 在原有对象上进行操作,效率极高 } String result = sb.toString(); -
避免不必要的字符串创建:
- 尽量使用字面量而非
new关键字。 - 对于在循环中不变的字符串,可以提到循环外部。
- 尽量使用字面量而非
-
谨慎使用
String.intern():intern()方法会尝试将字符串放入全局共享的常量池,这个过程可能很耗时(需要同步)。- 它会永久占用内存,因为常量池中的对象不会被 GC 回收。
- 通常只在处理大量重复且内容相同的字符串时(如解析大型 XML/JSON 文件时的大量短键)才考虑使用,以换取内存空间的节省。
| 特性 | 描述 | 实现方式 | 优点 | 缺点/注意事项 |
|---|---|---|---|---|
| 不可变性 | 不可变 | final 类, final 数组, 无修改方法 |
线程安全、可被哈希缓存、成为 HashMap 的完美键 |
频繁修改时会产生大量新对象,性能差 |
final 类 |
不能被继承 | public final class String |
保证 String 行为的稳定性和不变性 |
失去了通过继承扩展功能的灵活性 |
| 字符数组优化 | 使用 byte[] 替代 char[] |
private final byte[] value + coder 标志 |
节省内存,特别是对 ASCII 字符 | 增加了处理逻辑的复杂性 |
| 字符串常量池 | 共享字符串字面量 | JVM 特殊内存区 | 节省内存、提高创建相同字符串的效率 | new 关键字会绕过池,可能导致重复对象 |
理解 String 类的这些实现细节,能帮助你在日常开发中做出更明智的决策,写出更高效、更健壮的代码。