(H1):Python KafkaUtils终极指南:从零到高并发消息处理的实践之路
Meta描述: 本文是Python开发者学习KafkaUtils的终极指南,从环境搭建、核心API使用,到生产环境中的高并发消息处理与最佳实践,手把手教你掌握Python与Kafka的集成,轻松应对大数据实时流处理挑战。

引言:为什么Python开发者必须掌握KafkaUtils?
在当今数据驱动的时代,实时数据流处理已成为构建现代化应用的核心能力,无论是用户行为分析、实时风控、物联网数据采集,还是微服务间的异步通信,Apache Kafka 都以其高吞吐、可扩展、持久化的特性,成为了事实上的行业标准。
对于Python开发者而言,如何优雅、高效地与Kafka进行交互?kafka-python 库无疑是首选,而其中,KafkaUtils(虽然在较新版本中其功能已被整合到更高阶的API中,但其核心思想依然是基础)及其代表的编程范式,是我们打开Kafka大门的钥匙。
本文将摒弃枯燥的理论,以“问题-解决-实践”为脉络,带你从零开始,系统性地掌握如何使用Python与Kafka进行通信,并深入探讨在生产环境中构建高并发、高可靠消息处理系统的关键技巧。
(H2)第一部分:准备工作——你的Python-Kafka开发环境
在开始编码之前,一个稳定的环境是成功的基石,本部分将指导你完成所有必要的准备工作。

环境要求
- Python环境: 推荐使用 Python 3.7+,以获得更好的性能和语法支持。
- Kafka集群: 你需要一个正在运行的Kafka集群,可以是本地单节点集群(用于学习),也可以是云上的分布式集群。
- 本地快速启动: 使用
Docker Compose是最简单的方式,网上有大量现成的docker-compose.yml文件,一键即可启动ZooKeeper和Kafka服务。
- 本地快速启动: 使用
安装核心依赖库
我们将使用最主流的 kafka-python 库,打开你的终端,执行安装命令:
pip install kafka-python
为什么是 kafka-python?
- 纯Python实现: 无需依赖C扩展,安装和部署极其简单。
- 功能全面: 完整支持Kafka的生产者、消费者、消费者组管理等功能。
- 社区活跃: 文档完善,问题响应及时,是Python生态中最成熟的Kafka客户端之一。
(H2)第二部分:核心实战——Python生产者与消费者详解
Kafka的核心交互模式就是“生产-消费”,让我们从最基础的“Hello, Kafka”开始。
创建主题
在发送和接收消息前,我们需要一个Kafka主题来承载消息,你可以使用Kafka的命令行工具创建:

# 进入Kafka容器内或Kafka安装目录的bin目录下 # 创建一个名为 'python-test-topic' 的主题,分区数为1,副本数为1 kafka-topics.sh --create --topic python-test-topic --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1
编写第一个消息生产者
生产者的任务是创建消息并将其发送到指定的Kafka主题。
from kafka import KafkaProducer
import json
# 1. 配置生产者
# bootstrap_servers: Kafka集群地址列表
# value_serializer: 消息值的序列化方式,Kafka只接受bytes,所以我们需要将Python对象(如字典、字符串)序列化。
producer = KafkaProducer(
bootstrap_servers=['localhost:9092'],
value_serializer=lambda v: json.dumps(v).encode('utf-8') # 将字典序列化为JSON字符串再转为bytes
)
# 2. 发送消息
# topic: 目标主题
# value: 消息内容
for i in range(5):
message = {'user_id': f'user_{i}', 'message': f'Hello Kafka from Python! Message No.{i}'}
# send() 方法是异步的,它会立即返回一个Future对象
future = producer.send('python-test-topic', value=message)
# 可以通过 future.get() 阻塞等待并获取发送结果(包括异常)
try:
record_metadata = future.get(timeout=10)
print(f"Message sent successfully to topic {record_metadata.topic} partition {record_metadata.partition} at offset {record_metadata.offset}")
except Exception as e:
print(f"Failed to send message: {e}")
# 3. 确保所有消息在程序退出前都已发送
# flush() 方法会阻塞,直到所有待发送的消息都成功发送或超时
producer.flush()
代码解读:
KafkaProducer: 生产者的核心类。bootstrap_servers: 连接到Kafka集群的入口,可以是多个地址以实现高可用。value_serializer: 关键! Kafka的底层协议是基于字节的,我们必须将任何Python对象(如字符串、字典)编码成bytes,这里我们使用json.dumps将字典转为JSON字符串,再.encode('utf-8')转为字节流。producer.send(): 异步发送消息,这是高吞吐量的关键,立即返回一个Future对象,可以通过它来获取发送结果。- `producer.flush()**: 强制将所有缓冲区的消息发送出去,这是一个好习惯,尤其是在程序结束时。
编写第一个消费者
消费者的任务是从Kafka主题中拉取并处理消息。
from kafka import KafkaConsumer
import json
# 1. 配置消费者
# bootstrap_servers: Kafka集群地址
# group_id: 消费者组ID,这是实现负载均衡和容错的关键,同一组内的消费者会共同消费一个主题的分区。
# auto_offset_reset: 当没有初始偏移量或偏移量在服务器上不存在时(消费者在一个已经被删除的分区上读取),该怎么办。
# 'earliest': 从分区的最早偏移量开始读取。
# 'latest': 从分区的最新偏移量开始读取。
# enable_auto_commit: 是否自动提交消费的偏移量,默认为True。
# True: 消费者会周期性地自动提交偏移量,简单,但可能导致消息丢失(在消费成功但提交前崩溃)。
# False: 需要手动调用 consumer.commit_sync() 或 consumer.commit_async(),更安全,但代码更复杂。
consumer = KafkaConsumer(
'python-test-topic',
bootstrap_servers=['localhost:9092'],
group_id='python-consumer-group-1',
auto_offset_reset='earliest',
enable_auto_commit=False, # 为了数据安全,我们选择手动提交
value_deserializer=lambda m: json.loads(m.decode('utf-8')) # 反序列化
)
# 2. 拉取并处理消息
print("Consumer started. Waiting for messages...")
for message in consumer:
# message 对象包含了丰富的元数据
print(f"Received message: {message.value}")
print(f"Partition: {message.partition}, Offset: {message.offset}")
# 模拟业务处理逻辑
# ... process the message ...
# 3. 手动提交偏移量
# 只有在消息成功处理后,才提交偏移量,这样即使消费者崩溃,消息也不会丢失。
try:
# commit_sync 是同步提交,会阻塞直到提交成功
consumer.commit_sync()
print("Offset committed successfully.")
except Exception as e:
print(f"Failed to commit offset: {e}")
代码解读:
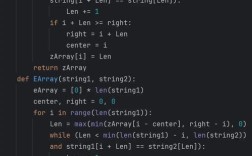
KafkaConsumer: 消费者的核心类。group_id: 核心概念! Kafka通过消费者组来实现负载均衡,一个主题的每个分区只能被同一个消费者组内的一个消费者消费,一个有4个分区的主题,如果消费者组内有2个消费者,那么每个消费者会消费2个分区,如果增加一个消费者到3个,Kafka会重新分配分区,其中一个消费者会消费1个分区,另外两个各消费1.5个(实际上会尽量均分)。auto_offset_reset: 决定了消费者启动时的行为。earliest适合从头消费数据(如数据修复),latest适合只消费新数据(如实时监控)。enable_auto_commit=False: 生产环境最佳实践,关闭自动提交,改为手动提交,可以确保“至少一次消费”(At-least-once delivery)语义,即消息不会丢失,但可能会被重复消费(需要业务层做幂等处理)。consumer.commit_sync(): 在处理完每条消息后调用,确保偏移量被更新,如果处理失败,则不提交,这样Kafka重试时会再次发送这条消息。
(H2)第三部分:进阶与生产实践——构建高并发、高可靠的系统
掌握了基础后,我们需要考虑如何让我们的系统更健壮、性能更高。
实现高并发的消费者
对于高吞吐量的场景,单个消费者进程可能成为瓶颈,我们可以利用多线程或异步IO来并发处理消息。
使用 concurrent.futures.ThreadPoolExecutor 的示例:
from kafka import KafkaConsumer
from concurrent.futures import ThreadPoolExecutor
import json
import time
# 消费者配置 (同上)
consumer = KafkaConsumer(
'python-test-topic',
bootstrap_servers=['localhost:9092'],
group_id='python-consumer-group-2',
auto_offset_reset='earliest',
enable_auto_commit=False,
value_deserializer=lambda m: json.loads(m.decode('utf-8'))
)
# 消息处理函数
def process_message(message):
"""模拟一个耗时的消息处理过程"""
print(f"Processing message {message.value['message']} on thread {threading.get_ident()}")
time.sleep(2) # 模拟处理耗时
print(f"Finished processing message {message.value['message']}")
# ... 业务逻辑 ...
return True
# 使用线程池来并发处理
with ThreadPoolExecutor(max_workers=4) as executor:
print("Consumer started with thread pool. Waiting for messages...")
for message in consumer:
# 将消息提交给线程池中的某个线程去处理
future = executor.submit(process_message, message)
# 主线程继续拉取新消息,不等待处理完成
# 为了简化,这里我们假设处理总是成功,并提交偏移量
# 在实际生产中,你需要根据 future.result() 的结果来决定是否提交
try:
# future.result() 会阻塞直到任务完成,但我们不在这里调用,而是异步处理
# 这里我们简化处理,直接提交
consumer.commit_sync()
except Exception as e:
print(f"Error in processing or committing: {e}")
关键点:
- 分离拉取与处理: 主线程只负责从Kafka拉取消息,并将其快速地丢给一个工作线程池,主线程不关心消息何时处理完毕,从而实现了高并发拉取。
- 偏移量提交的复杂性: 这种模式下,偏移量的提交变得复杂,你需要在所有处理该消息的线程都成功完成后,才能提交偏移量,一个常见的策略是:
- 主线程拉取消息,放入一个内存队列(如
queue.Queue)。 - 工作线程从队列中取出消息并处理。
- 当一个工作线程处理完消息后,它可以将该消息的偏移量标记为“已处理”。
- 主线程定期检查,如果某个偏移号之前的所有消息都已处理,则提交该偏移量。
- 主线程拉取消息,放入一个内存队列(如
最佳实践与避坑指南
-
优雅关闭: 消费者应该能够优雅地关闭,捕获
KeyboardInterrupt(Ctrl+C) 信号,在退出前调用consumer.close(),确保最后一次的偏移量被提交。try: for message in consumer: # ... except KeyboardInterrupt: print("Consumer is shutting down...") finally: consumer.close() -
处理消息重复: 当
enable_auto_commit=False时,如果消费者在处理完消息后、提交偏移量前崩溃,那么下次重启时,Kafka会重新发送这条消息,你的业务逻辑必须是幂等的,使用数据库的唯一键、Redis的SETNX或版本号来避免重复处理导致的问题。 -
合理配置消费者数量: 一个消费者组内的消费者数量不应超过主题的分区数量,因为每个分区最多只能被一个消费者消费,多余的消费者将处于空闲状态。
-
监控与告警: 监控你的消费者滞后情况,可以通过
consumer.assignment()和consumer.position(partition)来获取消费者当前消费的偏移量,并与Kafka日志的结束偏移量进行比较,判断是否滞后。
(H2)第四部分:总结与展望
本文系统地介绍了如何使用Python(kafka-python库)与Apache Kafka进行交互,从一个简单的“生产-消费”模型,逐步深入到生产环境中的高并发、高可靠性实践。
核心要点回顾:
kafka-python是Python操作Kafka的利器。- 生产者是异步的,通过
value_serializer处理序列化,通过flush()确保消息发出。 - 消费者的核心是消费者组,它实现了负载均衡。
- 手动提交偏移量 (
enable_auto_commit=False) 是保障数据不丢失的关键,但需要业务实现幂等性来应对重复消息。 - 多线程/异步IO 是提升消费者吞吐量的有效手段,但需谨慎处理偏移量提交逻辑。
未来展望:
随着业务的发展,你可能需要探索更高级的用法,
- Exactly-Once Semantics (精确一次语义): 结合事务性Kafka生产者和幂等消费者来实现。
- Schema Registry: 使用
confluent-kafka-python等库集成Schema Registry,实现自动化的序列化/反序列化,并确保数据格式的一致性。 - 流处理框架: 学习使用 Apache Flink 或 Spark Streaming,它们构建在Kafka之上,提供了更强大的窗口计算、状态管理等流处理能力。
希望这篇指南能成为你Python与Kafka之旅的坚实起点,动手去构建属于你自己的实时数据管道吧!
(文章末尾可添加评论区,鼓励用户提问和交流)