第一部分:数据挖掘与机器学习核心概念
什么是数据挖掘?
数据挖掘是从大量数据中通过算法搜索隐藏于其中信息的过程,它结合了机器学习、统计学、数据库和可视化等技术,目的是发现数据中的“模式”和“知识”。

(图片来源网络,侵删)
什么是机器学习?
机器学习是人工智能的一个分支,它使计算机系统能够通过数据“学习”和改进,而无需进行显式编程,在数据挖掘中,我们使用机器学习模型来:
- 预测:预测未来的结果(如客户是否会流失、明天天气如何)。
- 描述:理解数据内部的结构和关系(如将客户分成不同群体)。
数据挖掘流程
一个典型的数据挖掘项目通常遵循以下步骤:
- 业务理解:明确目标。
- 数据理解与收集:获取原始数据。
- 数据预处理:这是最关键也最耗时的步骤,包括:
- 数据清洗:处理缺失值、异常值。
- 数据集成:合并多个数据源。
- 数据转换:归一化、标准化、离散化。
- 特征工程:创建、选择、提取对模型有用的特征。
- 模型构建:选择合适的算法并训练模型。
- 模型评估:使用测试集评估模型性能(准确率、精确率、召回率等)。
- 部署与应用:将模型集成到实际业务系统中。
第二部分:核心实用机器学习技术及分类
数据挖掘中的机器学习任务主要分为三大类:监督学习、无监督学习和 强化学习,我们重点讨论前两者。
A. 监督学习
模型从已标记的数据中学习,数据集中包含特征和对应的标签。

(图片来源网络,侵删)
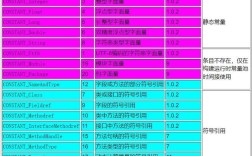
| 任务 | 描述 | 常用算法 | Java实现库 |
|---|---|---|---|
| 分类 | 预测一个离散的类别标签(如:是/否,A/B/C类) | - 逻辑回归 - 支持向量机 - 决策树 - 随机森林 - K-近邻 - 朴素贝叶斯 |
Weka, Deeplearning4J, Tribuo |
| 回归 | 预测一个连续的数值(如:房价、温度) | - 线性回归 - 岭回归 - Lasso回归 - 支持向量回归 - 决策树回归 |
Weka, Tribuo, Tribuo (推荐) |
B. 无监督学习
模型从未标记的数据中学习,目标是发现数据内在的结构。
| 任务 | 描述 | 常用算法 | Java实现库 |
|---|---|---|---|
| 聚类 | 将数据分成不同的组,使得组内数据相似,组间数据相异 | - K-Means - DBSCAN - 层次聚类 |
Weka, Tribuo, Tribuo (推荐) |
| 关联规则 | 发现数据项之间的有趣关系(如:购买了A商品的客户也倾向于购买B商品) | - Apriori - FP-Growth |
Weka, Tribuo (需额外实现或找特定库) |
| 降维 | 在保留大部分信息的前提下,减少数据的特征数量 | - 主成分分析 - t-SNE |
Weka, Tribuo, ND4J |
第三部分:Java 实现生态与工具选择
Java在数据挖掘和机器学习领域拥有强大的生态系统,选择哪个库取决于你的需求。
Weka (Waikato Environment for Knowledge Analysis)
- 简介:最经典、最著名的Java机器学习库,尤其适合学术研究和快速原型验证。
- 优点:
- 非常全面的算法集合(分类、回归、聚类、关联规则等)。
- 提供图形化界面,无需编写代码即可探索数据。
- 文档丰富,社区庞大。
- 缺点:
- API设计有些老旧。
- 性能对于大规模数据集可能不是最优。
- 适用场景:教育、数据探索、原型验证。
Tribuo
- 简介:由Oracle Labs开发,是现代、高性能的Java机器学习库,被认为是Weka的现代化继任者。
- 优点:
- 基于现代Java特性,API设计清晰、可扩展。
- 性能极高,利用多核CPU进行并行计算。
- 与ND4J(深度学习库)无缝集成,支持从传统机器学习到深度学习的平滑过渡。
- 支持在线学习和模型解释性等高级特性。
- 缺点:
相较于Weka,生态系统和社区还在成长中。
- 适用场景:生产环境、高性能计算、需要集成深度学习的项目。
Deeplearning4J (DL4J) & ND4J
- 简介:专注于深度学习的Java库,ND4J是DL4J的数值计算库,类似于Python的NumPy。
- 优点:
- 功能强大的深度学习框架,支持各种神经网络(CNN, RNN, GAN等)。
- 可以与Spark集成,进行分布式训练。
- 支持导入和导出TensorFlow和Keras模型。
- 缺点:
主要专注于深度学习,传统机器学习算法支持不如Tribuo或Weka全面。
 (图片来源网络,侵删)
(图片来源网络,侵删) - 适用场景:图像识别、自然语言处理、语音识别等深度学习任务。
其他库
- Apache Spark MLlib:如果你已经在使用Spark进行大数据处理,MLlib是其内置的机器学习库,适合分布式机器学习。
- MOA (Massive Online Analysis):专注于流式数据和增量学习的框架。
推荐选择:
- 初学者/快速上手:Weka
- 生产环境/高性能需求:Tribuo
- 深度学习项目:Deeplearning4J + ND4J
- 大数据环境:Apache Spark MLlib
第四部分:Java 实现示例
下面我们使用 Weka 和 Tribuo 这两个主流库,分别实现一个分类任务和一个聚类任务。
示例1:使用 Weka 进行鸢尾花分类
任务:根据鸢尾花的四个特征(花萼长度、花萼宽度、花瓣长度、花瓣宽度)来预测它属于哪个品种(Setosa, Versicolor, Virginica)。
步骤:
- 下载 Weka 库:https://www.cs.waikato.ac.nz/ml/weka/stable.html (下载
weka.jar) - 下载鸢尾花数据集:
iris.arff(Weka自带的数据格式,或从网上下载)
代码实现 (IrisClassifier.java)
import weka.classifiers.Classifier;
import weka.classifiers.Evaluation;
import weka.classifiers.trees.J48;
import weka.core.Instances;
import weka.core.converters.ConverterUtils.DataSource;
public class IrisClassifier {
public static void main(String[] args) throws Exception {
// 1. 加载数据
DataSource source = new DataSource("path/to/your/iris.arff"); // 替换为你的文件路径
Instances data = source.getDataSet();
// 设置数据集的类别属性索引 (最后一列是类别)
if (data.classIndex() == -1) {
data.setClassIndex(data.numAttributes() - 1);
}
// 2. 训练模型 - 我们选择J48决策树算法
Classifier classifier = new J48(); // J48是C4.5决策树的Java实现
classifier.buildClassifier(data);
// 3. 评估模型
Evaluation eval = new Evaluation(data);
eval.crossValidateModel(classifier, data, 10, new java.util.Random(42)); // 10折交叉验证
// 4. 输出评估结果
System.out.println("=== 模型评估结果 ===");
System.out.println(eval.toSummaryString());
System.out.println("\n=== 详细分类报告 ===");
System.out.println(eval.toClassDetailsString());
System.out.println("\n=== 混淆矩阵 ===");
System.out.println(eval.toMatrixString());
// 5